
本文作者:Tianheng Ni
本文分类:随笔 浏览:4706
阅读时间:2610字, 约3-4.5分钟
本文也见于:https://blog.csdn.net/EricNTH/article/details/104840887
同见于:https://www.cnblogs.com/EricNTH/p/12508406.html
作者均为小编本人,请不要误会!
Hello大家好,我们又见面了!
这是我写的第一篇python文章,还望各位朋友们多多指教!
废话不多说,我们进入正题。
本文为EricNTH的原创博客,转载请注明出处!
目录
Http请求头(header)
写过python爬虫的人都知道,在用requests发送http请求时,都会有一个header。里面装了这次http请求的头信息。要想做好爬虫,设计好请求头是非常重要的,否则万一被反爬虫查出(很容易),得不偿失。
以下简介来自百度:
HTTP客户程序(例如浏览器),向服务器发送请求的时候必须指明请求类型(一般是GET或者POST)。如有必要,客户程序还可以选择发送其他的请求头。大多数请求头并不是必需的,但Content-Length除外。对于POST请求来说Content-Length必须出现。 (HttpServletRequest)
接下来由我来给大家介绍http请求头中(可能是)最重要的两部分,也是最容易被反爬虫利用的两部分。你若不想让自己被发现是爬虫,下面就请听好啦~
User-agent
User-Agent 首部包含了一个特征字符串,用来让网络协议的对端来识别发起请求的用户代理软件的应用类型、操作系统、软件开发商以及版本号。
一般,我们写爬虫时,User-agent总是必不可少的.。
你可以通过它来伪装成浏览器在访问。
一般,user-agent里装的时访问的浏览器,以及版本号等。
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) ''Chrome/45.0.2454.85 Safari/537.36 115Browser/6.0.3''Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10_6_8; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50''Mozilla/5.0 (Windows; U; Windows NT 6.1; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50','Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0)''Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)''Mozilla/5.0 (Windows NT 6.1; rv:2.0.1) Gecko/20100101 Firefox/4.0.1''Opera/9.80 (Windows NT 6.1; U; en) Presto/2.8.131 Version/11.11''Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_0) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11''Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; SE 2.X MetaSr 1.0; SE 2.X MetaSr 1.0; .NET CLR 2.0.50727; SE 2.X MetaSr 1.0)'Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Trident/5.0''Mozilla/5.0 (Windows NT 6.1; rv:2.0.1) Gecko/20100101 Firefox/4.0.1'
以上这些是我有一次写爬虫的时候到网上搜到的一些,可见,又长又多啊~ 如果大家有需要用的,建议直接在我这里复制或上网搜,万一写错了(太容易了),那说不定就被识别出来了呢~【就尴尬了】
大家看到了,里面写的确实是浏览器名和版本,还有操作系统,电脑,语言,项目…
【移动后新增内容】
那么我们平时不可能用python上网,那么我们在正常浏览网页的时候如何更改UA呢?
下面我们就来看一看。(以Chrome浏览器为例,应该所有Chromium内核的浏览器都可以这样)
在键盘上按下F12键(或者右键选择“检查”),进入开发者菜单。如图所示:
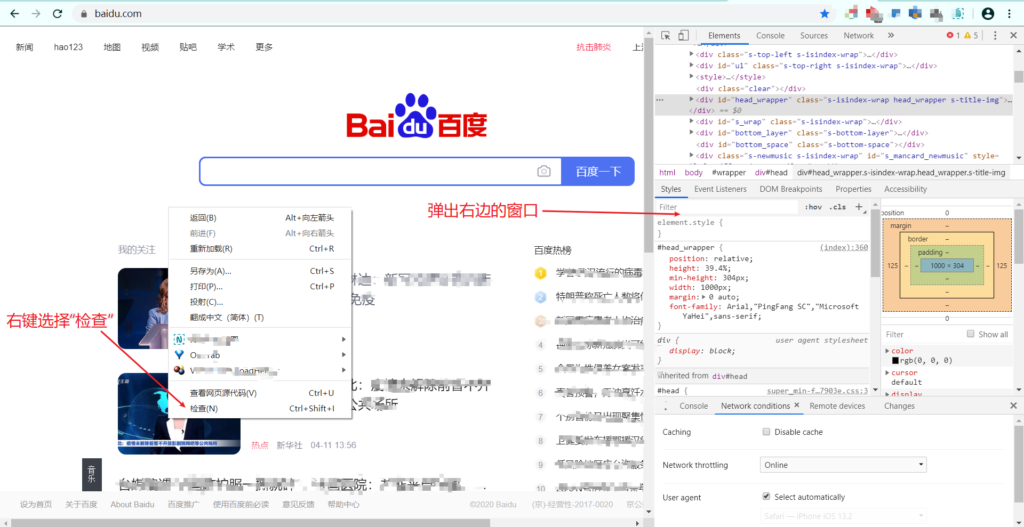

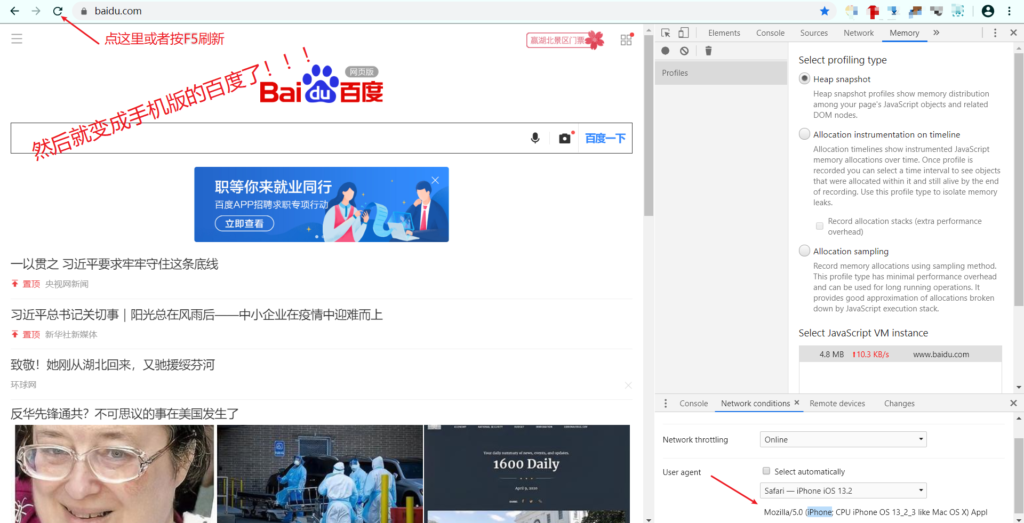
修改箭头指向的地方即可!
好了,下面我们进入下一个部分——referer。
Referer
HTTP Referer是header的一部分,当浏览器向web服务器发送请求的时候,一般会带上Referer,告诉服务器该网页是从哪个页面链接过来的,服务器因此可以获得一些信息用于处理。
这个因该还算好理解,比如你从CSDN首页看到了我的这篇文章,然后进来了,你这次访问的Referer就是https://www.csdn.net/。就是访问这个页面前你访问的页面,或者说是
顺便说一句,本来正确的拼写应该是Referrer,不知哪位大叔把它写错了,后来就成为惯例了【苦笑】,请千万不要和你的英语老师说REFERER!
有些反爬机制就会识别referer,看看是否正常(一般检查是否为空)。
那么什么时候referer会为空呢?
1.你直接从浏览器的地址栏中输入网址时(或者像Chrome的书签栏中);
2.你写python爬虫,没有指定referer时
由2得,我们一定要指定啊。。。
一般我们写referer时,都会写完整的(包括https://,www等),并且使用该网站的主页。
还有要注意,如果你写爬虫时,想伪装成从百度等搜索引擎搜到的,请不要写baidu.com,而要写那个访问的瞬间出现的link页面(link.baidu.com+bulabula一堆东西),否则聪明的反爬可能会识破!如果没心情去复制那一大长串链接,还不如伪装成从主页访问的呢。再说一句,那个link界面就是百度统计网页流量用的。
好了,今天有关于http请求中的header就讲完了,下一次我们会讲其它的内容,喜欢请点赞哦~
大家再见!
关于作者Tianheng Ni
- 卑微站长23564~ 苣蒻OIer,电脑爱好者,喜欢C++编程/折腾网站
- Email: eric_ni2008@163.com
- 注册于: 2020-04-05 07:11:36
收藏《Python爬虫教程之——详解http请求头中的User-agent与Referer》文章
点赞《Python爬虫教程之——详解http请求头中的User-agent与Referer》文章
收藏《Python爬虫教程之——详解http请求头中的User-agent与Referer》文章
点赞《Python爬虫教程之——详解http请求头中的User-agent与Referer》文章
收藏《Python爬虫教程之——详解http请求头中的User-agent与Referer》文章
点赞《Python爬虫教程之——详解http请求头中的User-agent与Referer》文章