
本文作者:森岛船长
本文分类:随笔 浏览:1678
阅读时间:6670字, 约7.5-11分钟
我在之前一篇文章《吾将如闪电般归来》中讲述了自己犯错和赎罪的前因后果。然而赎罪进程似乎远比我想的来的重要。截至目前,我帮助21159 佘山完成了5个技术任务,也使自己的赎罪进度变成了6/10。最近的一个任务结果尤其重要,佘山自己在使用完程序之后都表示,”功能极其强大“,并建议我在这里发表文章来宣传(原文如此)一下。
于是,就有了这篇文章的诞生。
我帮助佘山完成的第一个任务是按人统计周与月发言折线图。也就是说,程序的效果为输入一个学号之后运用matplotlib模块显示出这个人在整个第三校群中每个周/月的发言折线图。
在extractor.py即将原始校群聊天记录通过正则表达式进行清洗的程序函数中,我添加了”按周和月判断对话片段“的方法。
if tempMonth is None:tempMonth=month
if tempMonth>=month:
#这里是真的懵,有几条记录似乎没有出现在应该出现的位置,例如2020-4跑到2022-4后面了
chattingEachMonth.append(schoolID)
else:
chattingAllMonths[tempMonth]=chattingEachMonth
chattingEachMonth=[]
chattingEachMonth.append(schoolID)
tempMonth=month
if tempWeek is None:tempWeek=weekStartTimestamp
if datetimeTime.timestamp()<tempWeek+weekDelta:
chattingEachWeek.append(schoolID)
else:
chattingAllWeeks[str(datetime.fromtimestamp(tempWeek))]=chattingEachWeek
chattingEachWeek=[]
chattingEachWeek.append(schoolID)
tempWeek=tempWeek+weekDelta方法其实很简单。对于month来说,需要考虑的是获取日期的前7位(即YYYY-mm格式,例如2020-02)。
tempMonth里面存储的是上一个月份的7位格式。如果当前这一条消息的月份格式和tempMonth相同,那么就可以把这条消息加入chattingEachMonth这个列表中。而如果当前这一条消息的月份格式在tempMonth之后,就可以开启一个新的chattingEachMonth列表,并将之前的列表存入chattingAllMonths这个二维数组中。
在编写程序中也遇到了一个较为恶心(我愿称之为恶心)的bug。在佘山在校群内部介绍他使用正则表达式判断出”聊天记录头“的时候,就有人对这种方法的准确性产生了怀疑。有人当即发表出了可以满足这个正则表达式的消息,这些消息也就不得不也被收录在了lines中。然而问题就出在这里。这些消息中有不少是以2020-04-......开头的,这些消息会使得tempMonth在2020-04和2022-04之间来回切换。好在至少没有出现2022-04之后月份的”假“聊天记录”头“,所以我这边不得不使用>=来判断是否更新而不是最为精准的==运算符。
对于week来说,需要考虑的不是从date中获取其他信息,因为一般来说从date中是判断不出当前是第几周的。对于这一点,我使用了datetime模块的timestamp功能,直接计算当前消息的timestamp。如果这个timestamp要在这一周开头的00:00:00和这一周结尾这一天的23:59:59之间,那么就可以将它收录进chattingEachWeek列表中。
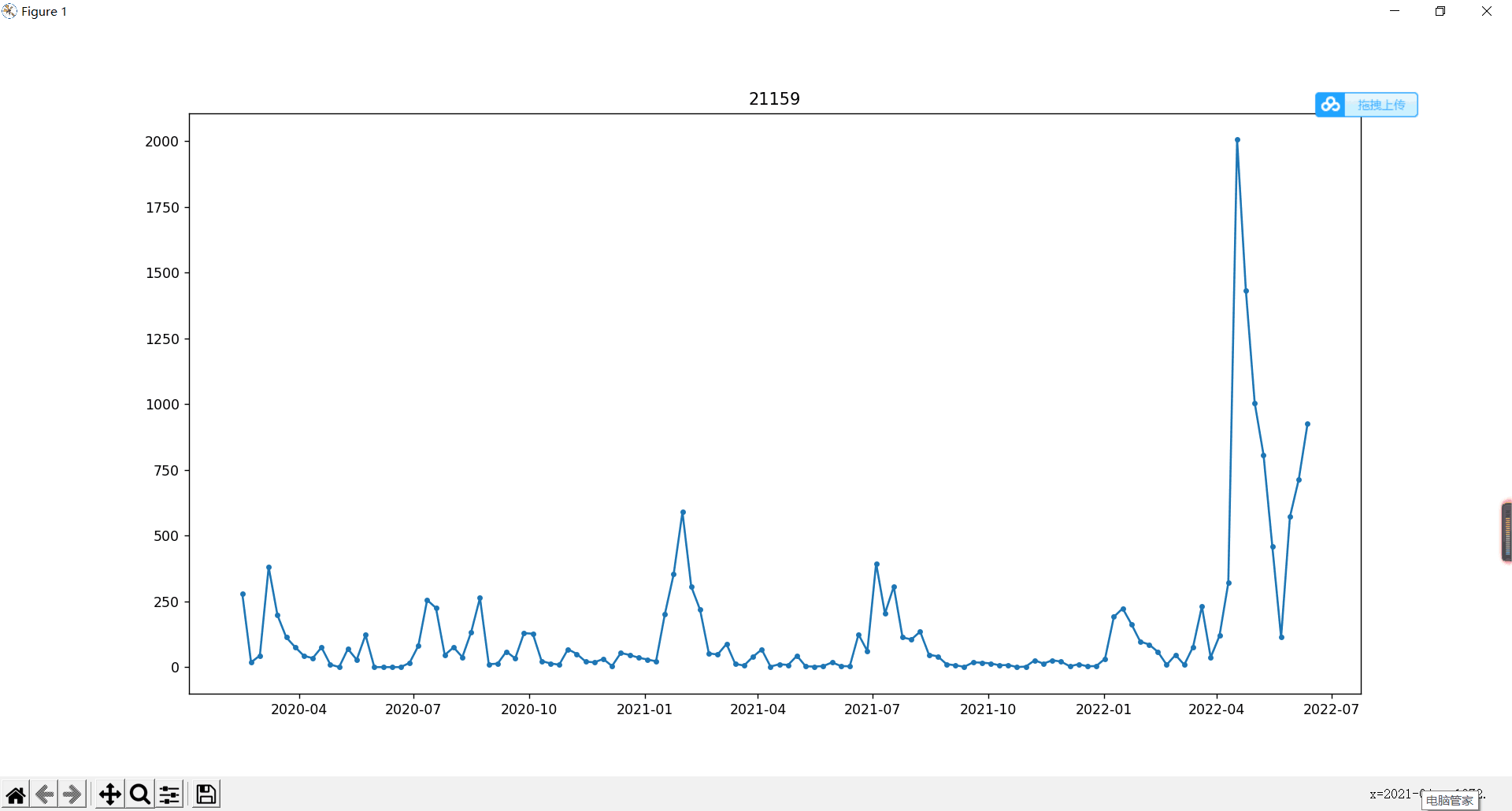
在经过一番周折之后(其实就是疯狂使用matplotlib),我终于完成了第一个任务。这里,我展示出21159 佘山(大统领)自己的周发言折线图表示尊敬。
第二个任务是按周统计个人发言比率图。
这个任务在第一个任务的基础上,只要修改一下展示代码即可,即将本来展示单人折线图的代码改为展示全部人员饼图的代码。于是,我在weekchart.py的基础上创作出了weekpie.py:
import numpy
from tools import *
from matplotlib import pyplot
from datetime import *
info=readInfoByJson()
chattingAllWeeks=info[6]
def paint(weekKey):
schoolID2freq:dict[str,int]={}
weekValue=chattingAllWeeks[weekKey]
for schoolID in weekValue:
if schoolID=='other':continue
if not schoolID in schoolID2freq:schoolID2freq[schoolID]=0
schoolID2freq[schoolID]+=1
sortedFreq=sortByValue(schoolID2freq)
schoolIDList=[]
freqList=[]
for i in range(len(sortedFreq)):
schoolIDList.append(sortedFreq[i][0])
freqList.append(sortedFreq[i][1])
freq2pie=numpy.array(freqList)
schoolID2label=schoolIDList
pyplot.pie(freq2pie,labels=schoolID2label,
labeldistance=0.5,radius=1.2,rotatelabels=True)
pyplot.title(weekKey[0:10])
pyplot.show()
if __name__ == '__main__':
for weekKey in chattingAllWeeks:
paint(weekKey)第三个任务与校群语料无关,所以直接快进到第四个任务。
在用Python完成第三个任务之后,佘山提出了让我用C++重写第三个任务的程序的设想。遗憾的是我的能力并不足够,所以(友好的)大统领给我换了个任务。在此我直接复制出佘山的原文:
21159 佘山主义的朝晖 2022/7/17 18:14:08
我想出个好的
21159 佘山主义的朝晖 2022/7/17 18:14:46
您能做一个按照特定的若干人物发言比例进行记录筛选的功能吗
21159 佘山主义的朝晖 2022/7/17 18:14:57
比如如果想找蘑达辩论
21159 佘山主义的朝晖 2022/7/17 18:15:07
就设置蘑菇>0.3
21159 佘山主义的朝晖 2022/7/17 18:15:14
达>0.3
21159 佘山主义的朝晖 2022/7/17 18:15:19
然后所有这样的片段
21159 佘山主义的朝晖 2022/7/17 18:15:21
都找出来
我自然不可能再次推诿了。于是我便开始构建思路。突然,一个东西跳入我的脑海——那是我之前在进行”对话统计友好度“时制作的以两分钟为间隔的对话分离器。
这个分离器和第一个任务有异曲同工之妙,连代码也十分相似。只不过在tempTime的更新上有一些变化——改为按照timeDelta(我设置为2min)判断分离的对话。即如果两句连续的话相隔超过2min,就将它们分为两个不同的对话。timeDelta暂定为2min是因为我觉得校群众位人士在讨论一个话题的时候大概率两句话间隔不会超过2min。
这时候之前写好的代码就派上用场了,我(简单然而复杂的)写好了这个筛选对话片段的程序。在下面,我将分离器(还是在extractor.py中)和筛选程序即chattingpart.py展示出来。
if tempTime is None:
tempTime=datetimeTime
chattingStartTime.append(str(datetimeTime))
if datetimeTime.timestamp()<tempTime.timestamp()+timeDelta:
#一个对话part还未结束
chattingEachPart.append(schoolID)
else:#一个对话part已结束,开启一个新的对话part
chattingEndTime.append(str(tempTime))
chattingStartTime.append(str(datetimeTime))
chattingAllTime.append(chattingEachPart)
chattingEachPart=[]
chattingEachPart.append(schoolID)
tempTime=datetimeTime#更新发言时间from tools import *
info=readInfoByJson()
chattingAllTime=info[4]
chattingSTTime=info[7]
def require(*args):
length=len(args)
schoolIDs:list[str]=[]
#probabilities:list[float]=[]
s2pDict:dict[str,float]={}
for id in range(0,length,2):
schoolID=args[id]
probability=args[id+1]
schoolIDs.append(schoolID)
s2pDict[schoolID]=probability
situations=0
parts=len(chattingAllTime)
for partId in range(parts):
correct=True
chattingEachPart=chattingAllTime[partId]
partlength=len(chattingEachPart)
if partlength<=10:continue
s2fDict:dict[str,int]={}
for schoolID in chattingEachPart:
if schoolID=='other':continue
if not schoolID in s2fDict:s2fDict[schoolID]=0
s2fDict[schoolID]+=1
for schoolID in s2pDict:
if not schoolID in s2fDict:
correct=False
break
if s2fDict[schoolID]/partlength<=s2pDict[schoolID]:
correct=False
break
if correct:
#print(chattingEachPart)
situations+=1
print('此片段开始时间:%s'%chattingSTTime[0][partId])
print('此片段结束时间:%s'%chattingSTTime[1][partId])
print('此片段共%d句话'%partlength)
for schoolID in schoolIDs:
print('学号:%s,片段中发言次数:%s,占比:%.5f'%
(schoolID,s2fDict[schoolID],s2fDict[schoolID]/partlength))
print('')
print('共%d个片段满足要求\n'%situations)
if __name__ == '__main__':
#print(len(chattingAllTime))
while True:
try:
studentnum=int(input('请输入您想了解的片段中有具体要求的学生个数:'))
arguments=[]
for i in range(studentnum):
schoolID=input('请输入您想了解片段中有具体要求的的学生学号:')
probability=float(input('请输入您希望这位学生的发言所占比率(0~1):'))
arguments.append(schoolID)
arguments.append(probability)
require(*arguments)
except Exception as e:
print('遇到错误:%s'%e)
print('请重新输入!')这个程序,至少在佘山眼中,取得了极大的成功。
21159 佘山主义的朝晖 18:51:52
特别是最后这个按比例检索
21159 佘山主义的朝晖 18:51:55
我觉得很强
另外,这个程序在我不懈的努力(或是无谓的尝试)后有了一些有趣的结果:
1.第三校群后期发言爆炸的蘑菇,wyd和森岛三人事实上极少同时进行辩论。只有两个片段满足三人的发言比率都>0.2,这个数字已经相对很普通了。
2.蘑菇和wyd的友谊果真”天长地久“。共有18个片段满足两人发言比率都超过了0.45。同时,有23个片段满足wyd发言比率超过了0.6,蘑菇发言比率超过了0.3;只有4个片段满足蘑菇发言比率超过0.6,而wyd发言比率超过0.3。可见,在整个第三校群的蘑达辩论过程中,wyd略胜一筹。
3.蘑菇独角戏现象严重。有19个片段满足蘑菇的发言比率超过了惊人的0.9,相比之下wyd超过0.9的片段就只有3个,还不如佘山的7个片段。而森岛显得格外微不足道,只有2个片段比率超过0.9,超过0.7的片段也只有15个,很明显在独角戏这一块,蘑菇几乎成为霸主。
4.在几个活跃人士中,森岛最靠近的实际上是蘑菇。对于两人发言比率都>0.3的情况,森岛和wyd,佘山各自只有一个片段,和李雪甚至都没有大型交集。相比之下,和蘑菇的13个片段反倒显得不少了。
另外一个值得注意的现象是我一直强调着的”森岛带动校群发展“。这个结论在第一个任务中得到了证实。几乎所有的活跃人士(比如蘑菇,wyd)在2022-04的发言曲线最为陡峭,这一段时间也刚好是我自己超级活跃的时间。5月之后我一蹶不振,很多活跃人士的发言曲线也就降了下来。
第五个任务的来源是这样的:佘山对我将timeDelta固定死(2min)的行为表示有些怀疑。他建议我将其改成“自适应的”。(原文如此)
21159 佘山主义的朝晖 2022/7/19 22:09:01
我觉得timeDelta直接设为两分钟
21159 佘山主义的朝晖 2022/7/19 22:09:03
不尽合理的
21159 佘山主义的朝晖 2022/7/19 22:31:28
我在考虑设计一种自适应的timedelta
然后他就给我布置了第五个任务。第五个任务其实可以算是对于timeDelta合理值的探索。他让我制作了两个图表:第一个图表,横坐标为消息的条数(1~387824),对于横坐标为i的点,它的纵坐标是第i条记录和第i+1条记录之间的时间差。第二个图表,横坐标为时间差,纵坐标则是时间差实例出现的个数。例如如果有10000组消息的时间差为2s,则横坐标为2的点纵坐标为10000。
两个图表我顺利的完成了。第一个图表,如佘山的预料一般,“应该会上蹿下跳的”。为了把体验变得更好,佘山让我将纵坐标按照降序排列。
得到的结果,只能说,是可喜的。在时间差小于50s之后,整个曲线分布极为平滑,如同佘山所说,“这个图像几乎可以用一个函数来表示的。”的确,这个图像和反比例函数的图像,从远处看,就是“不能说极其相似,只能说一模一样”。第二个图表得到的结果更令佘山赞叹。他让我作出了时间差从1s到50s(“那个时间差,好像是在50的时候,突然上升的”)的条形统计图。
这个条形统计图和前面的折线图几乎一样平滑,在15s~25s这个区间内部更是如此。这仿佛是更为准确的反比例函数图像。
遗憾的是,我无法将图像进行展示,想看这几张图的,可以校群at我或者私我。
第五个任务就这样圆满结束了。不过也不能说是圆满,因为似乎还没能做出佘山口中”自适应的timedelta“。佘山自己也这样说:
”所以你觉得timedelta要改吗“”可能吧(自问自答)“
最后写写后期的发展空间吧。估计这个程序还是逃不过佘山Word2Vec(令我捂脸的)的老路。(此处没有任何讽刺我们伟大的大统领的意思)机器学习这一块真的挺令我头疼的,等真到了那一步,估计主要的编写者就要变回佘山自己了。
所以,趁还能写,多写写吧。
(全文完)
关于作者森岛船长
- 我只是一个略微魔怔的程序员兼动漫爱好者兼学霸中的学渣。
- Email: 1329913830@qq.com
- 注册于: 2022-07-12 06:16:13
森岛太强了😋
@Tianheng Ni 这评论时间有问题啊🤔
@Yuqi Huang 啧 这好像是凌晨😅