
本文作者:旅菇佘侨159
本文分类:暂无分类 浏览:2661
阅读时间:15104字, 约17-25分钟
注:科忒尼察(Kotenyca)为虚构地名,是“佘山国”的一座经济发达的城市。在这里引用的灵感来自于乌克兰战争的新闻:乌西城市利沃夫的科技企业为前线捐助3D打印机,并为用神经网络分析军事情报提供指导。“利沃夫”(波兰语叫Lwow,Eu4里就这么标了)这个古老的名字听起来那么遥远、神秘,以至于有些童话色彩——然而那里也有科技企业,也有程序员,也在利用着深度学习技术。这就产生了一种奇妙的陌生感和反差感。
最近,HYwiki方兴未艾。我作为wiki的管理员之一,也对该地流连忘返。在同学们各自叙述的各种璀璨的班级文化中,我注意到了228人喜欢玩的小游戏:皇后棋。这款游戏抽象而简洁,但富有趣味性,局面变化多样,似乎是相当可玩的。于是在1月13日,我决定使用Python来编写此游戏,而我更终极的目标,则是为其开发一款AI,这样能够让我们以前所未有的深度来探索这个游戏。
皇后棋的核心在于国际象棋里的“皇后”这个棋子,它能够在方形晶格中沿横、竖、以及对角线方向移动。皇后棋分为单后棋和多后棋,其中多后棋中最常见的形式是双后棋。
单后棋使用一个8*8的棋盘,两名玩家依次移动皇后。移动时,皇后经过的格子,以及最后停留的格子便会被“挖去”,以后就不能停留在上面或者经过。最后,哪名玩家不能够合法移动皇后,那么这方就赢了。多后棋的规则类似,不过几个人分别操纵自己的后,获胜的是最后一个还能合法移动皇后的人。而且,多后棋中不能移动到能被其他后攻击的位置。
我先编写的是单后棋,因为它相对简单。我采用了Numpy库作为重要的辅助,因此不是纯粹的原生Python。我喜欢利用jupyter notebook来边实验边编写,减少最后debug时的难度。
首先必然需要一个矩阵来表示棋盘,然后一个坐标来表示皇后的位置。其实皇后棋的状态最基本的也就这两样东西。
皇后棋编写的难点一个在于判定可以移动到的位置,一个在于在移动后进行挖去。对于第一个问题,其实有很多写法,比如在得到输入之后可以首先考虑该点是不是在皇后的八个正方向上并没有出图,从皇后当前坐标开始,模拟皇后的移动,看看中途是否会遇到被挖去的格子。不过,我最后的目的是要编写一个ai程序,而根据我对于深度学习算法的经验,这样的一个即时且高度迭代式的解决方案似乎很不方便(这种直觉的来源后面会解释)。
也是根据这样的经验,我最终采取了“Masking”法,即对于每一步都计算一个和棋盘同形的矩阵,包含了每一个点的可走与否的信息。而计算的方法则与上述的过程差不多。这里我最初的方案是将八个方向的“单位向量”(就是位移-1,0或者1)先储存在一个数组里,然后对于每一个方向循环移动,直至出图。我不得不写了八个循环,然后一开始要么会出图,要么会在离边界一格的地方停下,而且每次改都得改八处,实在是太烦!因此很快我就采用了一种更优化的方法。
#最初的写法
def action_masking(board,coords):
n_board = board
mask = np.zeros(board.shape)
x = coords[0]
y = coords[1]
state = 0
n_x = x
n_y = y
while n_x<7 and state!=-1:
n_x+=1
state = n_board[n_x,n_y]
if state != -1:
mask[n_x,n_y]=np.inf
state = 0
n_x = x
n_y = y
while n_y<7 and state!=-1:
n_y+=1
state = n_board[n_x,n_y]
if state != -1:
mask[n_x,n_y]=np.inf
…………节约篇幅
state = 0
n_x = x
n_y = y
while n_x<7 and n_y>0 and state!=-1:
n_x+=1
n_y-=1
state = n_board[n_x,n_y]
if state != -1:
mask[n_x,n_y]=np.inf
state = 0
n_x = x
n_y = y
while n_x>0 and n_x<7 and n_y>0 and n_y<7 and state!=-1:
n_x-=1
n_y+=1
state = n_board[n_x,n_y]
if state != -1:
mask[n_x,n_y]=np.inf
return mask优化的写法是将边界判定语句先包装成一个函数cond,然后把迭代更新的部分也统一包装,这个函数作用很像探索,姑且叫explore。
def explore(board, x, y, d_x, d_y, mask):
state = 0
n_x = x
n_y = y
xlb = n_x > 0
xub = n_x < (board.shape[0] - 1)
ylb = n_y > 0
yub = n_y < (board.shape[1] - 1)
while cond(xlb, xub, ylb, yub, d_x, d_y) and state != -1:
n_x += d_x
n_y += d_y
state = board[n_x, n_y]
if state != -1:
mask[n_x, n_y] = 1
xlb = n_x > 0
xub = n_x < (board.shape[0] - 1)
ylb = n_y > 0
yub = n_y < (board.shape[1] - 1)
return mask
def cond(a, b, c, d, d_x, d_y):
return (d_x > -1 or a) and (d_x < 1 or b) and (d_y > -1 or c) and (d_y < 1 or d)
def action_masking2(board, coords):
n_board = board
mask = np.zeros(board.shape)
x = coords[0]
y = coords[1]
movements = [[1, 0], [0, 1], [-1, 0], [0, -1], [1, 1], [-1, -1], [1, -1], [-1, 1]]
for i in movements:
mask = explore(n_board, x, y, i[0], i[1], mask)
return mask好多了!下一个问题就是更改棋盘的问题。同样,我也采取了一种“计算矩阵”的思路,试图把每一次挖去的部分表示成一个增量(或者减量)矩阵,姑且称之为trace。这个问题其实比判定行动可行与否还要棘手一点。因为,我假设程序获得的唯一信息就是起始坐标和终止坐标两样。
我最后采取的,依赖numpy线性代数功能的方案多少有点离经叛道:对于矩阵上的每一个点,我计算它到起始点和终止点的向量,并用行列式判定共线性,同时用两个向量和总向量的点积来判定方向正确。现在想来可能这个方法不如运用和masking一致的迭代式方法。这里我一开始遇到了一些奇怪的问题,比如挖出来的方向是反的,或者有两个点莫名其妙漏挖了等等。不过最后还是解决了。这个函数我称之为“ripping”,因为很有一种皇后划过并撕破棋盘的感觉。
顺带一提,我在程序中对“皇后棋”的非正式英语名称是“Flight of Queen”(皇后的逃亡),缩写FoQ,因为单后棋的那种混乱很有一种逃杀的感觉。
有了这两个方法,皇后棋写出来便很容易了。编了一个界面玩了两局,我便开始考虑AI的问题。这便是我之前并不熟悉的强化学习(Reinforced Learning)问题。实际上我一开始考虑的是一种类似Policy Gradient的方法,直接对策略求导来训练某种神经网络。不过这个想法太模糊了,最后我不得不放弃。
然后我就想到了在围棋,象棋等上大放异彩的AlphaGo-AlphaZero方法。实际上这个想法还是挺令人畏惧的,因为虽然这两个成果已经有几年了,在深度学习领域算是老腊肉(划掉),但是毕竟还是引起社会广泛关注的精尖技术,我能够操作这样的算法吗?于是我的想法其实是退而求其次,考虑AlphaGo核心的MCTS(蒙特卡洛树搜索)算法。皇后棋相当简单,所以没准直接用经典MCTS就能搞出一个很强的AI。于是我就直接在浏览器开始搜mcts。有趣的是,MCTS似乎已经和AlphaZero深度绑定了,我搜出来的使用Jax实现的MCTS(叫做mctx),直接就是DeepMind搞出来为AlphaZero服务的模块。mctx自己给的案例写的十分复杂,我大概花了几个小时都没看懂,一度有点想放弃MCTS。后来我觉得pypi上可能还能淘到一些好东西,所以便又上pypi找MCTS包,果然找到了一款“只要写一个class就能在任意完全信息博弈领域进行搜索的”MCTS库,python类的多态继承大显神威!
这个MCTS要求写这几个成员函数:
get_possible_actions() get_current_player() take_action() is_terminal() get_reward()
其中第一个告诉这个经典智能体它能够采取的行动,用列表表示,第二个是一个getter,输出当前轮次,第三个则是最关键的走子。第四个判断棋局是否终结。最后一个是终结时输出一个奖励,用于搜索的叶子节点。单后棋写出来是这样:
class FlightOfQueen(BaseState):
def __init__(self):
self.board = np.zeros((8, 8))
self.currentPlayer = 1
self.coords = (0, 0)
self.rounds = 0
def get_current_player(self):
return self.currentPlayer
def masking(self):
return action_masking2(self.board, self.coords)
def get_possible_actions(self):
possibleActions = []
mask = self.masking()
#print(mask)
for i in range(self.board.shape[0]):
for j in range(self.board.shape[1]):
if mask[i][j] == 1:
possibleActions.append(Action(player=self.currentPlayer, coords=(i, j)))
if len(possibleActions) == 0:
possibleActions.append(Action(player=self.currentPlayer,coords=self.coords[self.currentPlayer]))
return possibleActions
def take_action(self, action):
newState = deepcopy(self)
newState.board = ripping(self.board, self.coords, action.coords)
newState.currentPlayer = self.currentPlayer * -1
newState.coords = action.coords
newState.board[action.coords[0], action.coords[1]] = 2
self.rounds += 1
return newState
def is_terminal(self):
mask = self.masking()
return mask.sum() == 0
def get_reward(self):
return self.currentPlayer * 20/(self.rounds+1)reward写法是为了鼓励智能体速战速决。
似乎MCTS算法在单后棋上效果还不错,经常能够击败我这个新手玩家。
我与22885讨论了一下这个成果。他告诉我单后棋实在太抽象,他们一般下双后棋。
于是我便考虑如何改造成双后棋。其实原则上并不难,只是变成维持两个坐标,然后把actionmasking变成一个自己的actionmask减去对方actionmask然后判定的操作就差不多。当然get_reward也要重写成和单后棋多少相反的方法,这个我纠结了好久。花了一点时间,带AI的双后棋也编出来了。

实际上这个MCTS算法也没有我说的那么轻松。一开始他经常会弹出一个错误,叫“Should Never Reach Here”,是他内部定义的一个catch error。然而显然这个提示对于debug毫无帮助。实际上最后会发现,step里面各种令人瞠目结舌的错误都有可能导致这个问题,而他却没有更好的提示。还有一个常见错误是“No Possible moves in non_terminal state”,这个倒是好理解,就是游戏没结束,一方却没有可行动作了。和这些错误缠斗了我好一会。
然后我又回到了MCTX库那里。他给了一个外部链接,指向配套的AlphaZero项目。我之前一直在研究mctx自己给的井字棋样例,然而这么个简单的小游戏也让我很头疼。没想到,AlphaZero项目里给的井字棋案例令人豁然开朗,让我觉得:我也能训练AlphaZero!因为和那个经典MCTS包一样,这个库也是只要定义一个特殊的类,便可以使用它作为一个enviroment来强化学习我们的智能体!
于是我便首先开始研究如何用jax重构皇后棋代码,使这个版本的AlphaZero可以采用。各位可能对jax不熟悉,不过你们可能都知道PyTorch或者TensorFlow,Keras这样的深度学习框架(或者更粗暴地,“自动微分框架”)。Jax就是谷歌准备的下一代自动微分框架,有很大的潜力(所以DeepMind就带头采用)。Jax的魅力有很多,改天可以专门写文章介绍。比如,它包含Jax.numpy(jnp),也就是numpy能干的活他都能干。更重要的是,jnp可以在GPU、TPU上以高度并行化的方式运行,而numpy本身是针对CPU优化的。在特定条件下,jnp可以比np快上百倍。不仅如此,jnp的函数是可以直接求导的!没错,只要该函数完全由可微分算子复合而成,那么一个简单的grad算符就可以立刻告诉你这个函数的输出相对于其每一个输入的偏微分。同时,jax还鼓励一种函数式编程的范式,有时甚至有点像Haskell。Vmap算符更是强大,可以完全规避烦人的矩阵维度问题,轻松考虑batch dimension,拯救不擅长思考高位空间人类。听说jax还准备搞一个xmap,允许你直接给每一个轴命名,更是让此类问题成为过去。

总之,我开始用jnp改写双后棋。最后结果类似这样:(这个代码其实已经是我后期反复修改过的,一开始还不是这样)
class Ripper(pax.Module):
num_cols: int = 9
num_rows: int = 8
def __init__(self):
super().__init__()
self.all_coords = jnp.stack([jnp.repeat(jnp.arange(self.num_rows),repeats=self.num_cols),jnp.tile(jnp.arange(self.num_cols),reps=self.num_rows)],axis=0)
def __call__(self, board: jnp.array, coords: jnp.array, new_coords: jnp.array):
translation = new_coords - coords
coords_tile = jnp.tile(coords,reps=(self.num_cols*self.num_rows,1)).transpose()
new_coords_tile = jnp.tile(new_coords,reps=(self.num_cols*self.num_rows,1)).transpose()
temp_translation = self.all_coords - coords_tile
temp_translation2 = new_coords_tile - self.all_coords
#print(temp_translation.shape, temp_translation2.shape)
def vacuuming(trans, temp_trans,temp_trans2):
det = jnp.linalg.det(jnp.stack([trans, temp_trans]))
dire = jnp.logical_and(jnp.dot(temp_trans, trans) >= 0, jnp.dot(temp_trans2,trans) >= 0)
return jnp.logical_and(dire, jnp.abs(det)<=0.01).astype(jnp.int8)
trace = vmap(vacuuming, in_axes=(None,1,1))(translation, temp_translation,temp_translation2)
trace = trace.reshape((self.num_rows,self.num_cols))
return board - trace
class ActionMasker(pax.Module):
num_cols: int = 9
num_rows: int = 8
def __init__(self):
super().__init__()
self.movements = jnp.array([[1, 0], [0, 1], [-1, 0], [0, -1], [1, 1], [-1, -1], [1, -1], [-1, 1]], dtype=jnp.int8)
def explore(self,board, x, y, d_x, d_y, mask):
def cond(val):
state, x, y, d_x, d_y, conds, board, mask = val
del x, y, board, mask
d_conds = jnp.array([d_x > -1 , d_x < 1, d_y > -1, d_y < 1], dtype=jnp.bool_)
conds = jnp.logical_or(d_conds,conds)
conds = jnp.logical_and(conds[:2],conds[2:])
conds = jnp.logical_and(conds[0],conds[1])
return jnp.logical_and(conds, state!=-1)
def probe(val):
state, x, y, d_x, d_y, conds, board, mask = val
x += d_x
y += d_y
state = board[x, y]
mask = jnp.where(state != -1,mask.at[x,y].set(1),mask)
conds = jnp.array([x > 0, x < (board.shape[0] - 1), y > 0, y < (board.shape[1] - 1)], dtype=jnp.bool_)
val = state, x, y, d_x, d_y, conds, board, mask
return val
conds = jnp.array([x > 0, x < (board.shape[0] - 1), y > 0, y < (board.shape[1] - 1)], dtype=jnp.bool_)
container = 0, x, y, d_x, d_y, conds, board, mask
state, x, y, d_x, d_y, conds, board, mask = while_loop(cond,probe,container)
return mask
def __call__(self, board, coords):
n_board = jnp.reshape(board,(self.num_rows,self.num_cols))
mask = jnp.zeros_like(n_board)
x = coords[0]
y = coords[1]
def oct_explore(n_board, x, y, movement):
return self.explore(n_board, x, y, movement[0], movement[1], mask)
mask = vmap(oct_explore,in_axes=(None,None,None,0))(n_board,x,y,self.movements).sum(axis=0)
return mask
class FlightOfQueenGame(Enviroment):
"""FOQ game environment"""
board: chex.Array
who_play: chex.Array
terminated: chex.Array
recent_boards: chex.Array # a list of recent positions
winner: chex.Array
num_cols: int = 9
num_rows: int = 8
num_recent_positions: int = 4
def __init__(self, num_cols: int = 9, num_rows: int = 8):
super().__init__()
self.masker = ActionMasker()
self.ripper = Ripper()
self.board = jnp.zeros((num_rows, num_cols), dtype=jnp.int32)
self.recent_boards = jnp.stack([self.board] * self.num_recent_positions)
self.who_play = jnp.array(0, dtype=jnp.int32)
self.terminated = jnp.array(0, dtype=jnp.bool_)
self.winner = jnp.array(0, dtype=jnp.int32)
self.count = jnp.array(0, dtype=jnp.int32)
self.coords = jnp.array([[0,0],[7,8]],dtype=jnp.int32)
self.all_coords = jnp.stack([jnp.repeat(jnp.arange(self.num_rows),repeats=self.num_cols),jnp.tile(jnp.arange(self.num_cols),reps=self.num_rows)],axis=0)
self.reset()
def num_actions(self):
return self.num_cols * self.num_rows
def duo_mask(self, whom):
mask = self.masker(self.board, self.coords[whom])
mask = mask - self.masker(self.board, self.coords[(whom + 1) % 2])
return mask.flatten()
def invalid_actions(self) -> chex.Array:
return self.duo_mask(self.who_play) <= 0
def reset(self):
self.board = jnp.zeros((self.num_rows, self.num_cols), dtype=jnp.int32)
self.recent_boards = jnp.stack([self.board] * self.num_recent_positions)
self.who_play = jnp.array(0, dtype=jnp.int32)
self.terminated = jnp.array(0, dtype=jnp.bool_)
self.winner = jnp.array(0, dtype=jnp.int32)
self.count = jnp.array(0, dtype=jnp.int32)
@pax.pure
def step(self, action: chex.Array) -> Tuple["FlightOfQueenGame", chex.Array]:
"""One step of the game.
An invalid move will terminate the game with reward -1.
"""
invalid_move = self.duo_mask(self.who_play)[action] <= 0
new_coords = self.all_coords[:,action]
#self.board = self.board.at[self.coords[self.who_play, 0]*9+self.coords[self.who_play, 1]].set(-1)
board_ = self.ripper(self.board, self.coords[self.who_play],new_coords)
board_ = jnp.clip(board_,-1,2)
self.coords = self.coords.at[self.who_play].set(new_coords)
self.board = select_tree(self.terminated, self.board, board_)
self.recent_boards = jnp.concatenate((self.recent_boards[1:], self.board[None]))
self.winner = jnp.where((self.duo_mask(self.who_play)<=0).sum() == 0,-1,0)
reward_ = jnp.where(self.who_play == 0,self.winner,-self.winner)
# increase column counter
self.who_play = 1 - self.who_play
self.count = self.count + 1
self.terminated = jnp.logical_or(self.terminated, reward_ != 0)
self.terminated = jnp.logical_or(
self.terminated, self.count >= self.num_cols * self.num_rows
)
self.terminated = jnp.logical_or(self.terminated, invalid_move)
reward_ = jnp.where(invalid_move, -1.0, reward_)
return self, reward_
def render(self) -> None:
"""Render the game on screen."""
#board = jnp.reshape(self.board,(self.num_rows,self.num_cols))
board = self.board
board = board.at[self.coords[self.who_play, 0], self.coords[self.who_play, 1]].set(1)
board = board.at[self.coords[1-self.who_play, 0], self.coords[1-self.who_play, 1]].set(2)
print(self.observation())
for row in range(self.num_rows):
for col in range(self.num_cols):
if board[row, col].item() == 1:
print("X", end=" ")
elif board[row, col].item() == -1:
print("O", end=" ")
elif board[row, col].item() == 2:
print("A", end=" ")
else:
print(".", end=" ")
print()
print()
def neutral_obs(self, whom) -> chex.Array:
board = jnp.zeros_like(self.board)
board = board.at[self.coords[whom,0],self.coords[whom,1]].set(1)
board = board.at[self.coords[1-whom,0],self.coords[1-whom,1]].set(-1)[None]
coord_visual = self.duo_mask(whom).reshape((self.num_rows,self.num_cols))[None]
return jnp.concatenate([self.recent_boards,board,coord_visual])
def observation(self) -> chex.Array:
#return jnp.reshape(board, (self.num_rows, self.num_cols))
return self.neutral_obs(0)
def canonical_observation(self) -> chex.Array:
return self.neutral_obs(self.who_play)
def is_terminated(self):
return self.terminated
def max_num_steps(self) -> int:
return self.num_cols * self.num_rows
def symmetries(self, state, action_weights):
action = action_weights.reshape((self.num_rows, self.num_cols))
#out.append((state, action_weights))
for i in [0,2]:
rotated_state = np.rot90(state, k=i, axes=(0, 1))
rotated_action = np.rot90(action, k=i, axes=(0, 1))
out.append((rotated_state, rotated_action.reshape((-1,))))
flipped_state = np.fliplr(rotated_state)
flipped_action = np.fliplr(rotated_action)
out.append((flipped_state, flipped_action.reshape((-1,))))
return out这就是已经完全按照a0要求编写的环境了。可以看到我把ripper和masker都变成了pax.module类,方便在foq类内部使用。
在jnp重写中,值得注意的一点是我尽量试图让操作并行化,而少用循环结构。比如,ripper部分我就构造了一个向量,直接72维代表每一个格点的坐标,然后用vmap与重叠72遍的起点/终点坐标相配计算。甚至explore部分的八向探索我也试图用单一lax进程优化。不过在jupyter环境下,测算下来这样改反而要花560ms执行一步,而原先只要430ms,反而慢了。不过我猜想这是因为一直在GPU和CPU之间搬运信息导致的减慢,如果jit加速之后一直在GPU上运行,应当是节省时间的。
虽然相关资料很多,这里还是很粗略很不专业的科普一下AlphaZero的原理。
AlphaZero的本质类似一种“受神经网络指导的MCTS搜索”。也就是它结合了两种算法,一种经典的,一种神经的。这个神经网络是双头的,首先会有一个骨干网络进行通用的局面分析,然后就分叉到两个头,一个叫策略头(Policy Head),输出一个类别型概率分布,其大小与动作空间的大小一样大。比如围棋有361个格点,外加轮空一种,共有362种操作,策略头输出的就是362维的向量,代表采取每一种动作的估算先验概率logit,后面会mask掉不可能的并softmax转为正式分布;另一个叫估值头(Value Head),只输出一个值,这个值代表当前局面下,可能的终局奖励:赢即为1,输为-1,平为0。围棋AI给的“胜率”参数其实就是估值头的输出。可以认为策略头是战术层面的,进行微观的,局部的判断,而估值头则是战略层面的,进行宏观的,大局的判断。
搜索树就受这双头蛇式的网络指导,不断进行模拟,模拟的早期尽量按照先验概率大的方法走,晚期按照估值较大的方法走(大概)。

在训练的一开始,神经网络的策略是完全随机的,也就是搜索树会随机落子。称之为“树”,是因为它将每一个局面(State)视为节点,而每一个操作将使其转移到下一个节点。游戏结束的局面称之为叶子节点(Leaf)。对于每一步,搜索树会模拟一定数量的局面,可能为32个或者64个,然后返回一个更优化的策略分布(更能导向胜利)。这一过程称之为“策略提升”。
智能体将每一局游戏下完,就会记录胜负,以及抽取一个局面记住当时自己估算的策略分布和搜索树返回的提升分布,并最终用这些东西(每一iteration可能下102400盘)进行一波有监督学习,目标是让自己的神经网络从任意给定局面直接看出最后胜负(估值头拟合胜负Reward),并让自己预估的策略更接近斟酌后的提升策略(策略头拟合策略),两者分别采用均方误差损失和交叉熵损失。然后用训练过后的神经网络指导自我对弈,周而复始。
对于皇后棋,我一开始认为它比较简单,因此就选用了一个比较简易的参数化方式:直接用一个两三层的MLP拟合,总共五万多参数量。网络的输入是一个76维向量,前72维代表每一个格子挖去与否的状态,后四维则粗暴地直接输入了两个后的坐标。
这里让我十分头疼的其实是对称性问题上。众所周知,很多数据其实都具有良好的对称性,比如围棋,其实把棋盘转一转,翻一翻,动作也就转一转、翻一翻就是了,是高度对称的,然而,比如卷积神经网络的卷积核,如果不加约束,只能自己慢慢摸索出“对称性”的概念,这会十分浪费(体现了深度学习的非智能性)。而DeepMind给的解决方案也只是“数据增强”层面上的,也就是在训练的时候把棋盘动作转一转,翻一翻一块输进去,我承认我不是很满意。理论上是完全可以在网络结构上加一些约束,来保证更好的equivariance的。我听说有一些数学家在做invariance和equivariance的深入研究,比如把一些群论的观点引入深度学习,这我是十分支持的,肯定能节约训练时间。而让我头疼的点在于我把棋盘展平成为一维向量的做法:这意味着我不得不把最后四维坐标先截下来,然后手算一个旋转和翻转,再和那72个能够正常旋转和翻转的数据“会师”,显得很不优雅。不过也只好这样做了。
这样就可以训练了。模仿他的样例对我自己的类输了一行指令,训练便开始了。
这里也并不一帆风顺。第一次我试的时候,发现每一次evaluation(新老智能体对弈),256番棋都是正好128胜128负。一看,竟然是坐标改变的算法没有写好,让两个人都没法移动,只能“发波”挖去格子困死对方。这太傻了。原来是jnp的小麻烦之一:数组完全没法直接修改(jnp arrays are immutable),必须用一个奇怪的“.at[x].set(a)”方法,返回一个更改了的复制品(所有的函数返回的都是复制品,原输入默认只读),所以如果忘写一个=赋值就会出问题。
改好后再试,后又发现出现大量的平局。按理说唯一出现平局的可能性是“行动超过72轮”(我设定的),然而棋盘上格子也就72个,即便两玩家一直乌龟爬,72轮也总能结束游戏。最后,又是一个离奇的错误:我设置障碍物是严格判定“-1”这个值,然而每一次后落在的位置会因为前后各减一次而变成“-2”,这就导致这个值永远的不成为障碍物,而且畅通无阻!所以我用一个jnp.clip语句修正了,让值最小就是-1。
然后我就在19日上午训练了大概一个半小时,只进行了23个iteration,来看看效果如何。训练时policy loss倒是一直在下降,从一开始2.56到最后只有0.9几了,说明拟合提升后的策略有进步。然而value loss居高不下甚至多有反复,徘徊在0.46附近,可谓“当局者迷”级别。现在想来是因为这两个值的数量级有一点区别,所以一开始很可能是策略损失主导了训练,值损失是第二位的(毕竟这还是个多目标优化问题!)。和这个ai下了一下,感觉傻傻的,很容易就击败了,可见是十分欠训练的。
不过我并不很打算继续训练这个试水的agent,而是用更强的网络打造一个好一点的。我原先想直接用ResNet,可是发现那个云平台CuDNN版本太低,没法调用tf后台执行卷积,又不怎么支持升级这种半硬件内容。所以我不得不想办法自己搞一个土ResNet,一个“没有卷积的卷积神经网络”出来,目前已经有了一定的进展。大致思路是按照长、宽维度展平用MLP做成“条状卷积”,然后进行残差连接,模仿ResNet的残差块。不过对于Batch Norm我还有一些实践上的困惑,可能需要实验一下来解答。
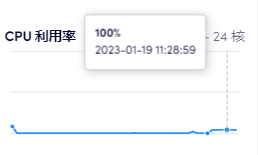
总之这就是目前为止的成果了。下一步有几个方向,一方面是继续训练,一方面是扩展到其他的棋类,比如248宣棋。
欢迎大家来和我交流!
关于作者旅菇佘侨159
- 退学,成群结队,连连骂
- Email: jiazhibai@hsefz.cn
- 注册于: 2022-05-25 00:14:29