
本文作者:旅菇佘侨159
本文分类:Huayu2Vec工程 计算机技术 浏览:1204
阅读时间:9199字, 约10-15.5分钟

一.引言
距离我在bilibili发表一万多字的《基于机器学习的“华育校友营”QQ群人员交互分析报告》已经过去了整整2个月了。我仍然没能回到学校(笑),所以在这两个月中,我又在这个项目上进行了多方面、多层次的完善和推进。在这一过程中,我有幸得到了各位校群群友热情的反馈和踊跃的帮助,我对此不胜感激。正如你们注意到的那样,我给项目取了一个趣味而不失特色的新名字:【Huayu2Vec工程】,暗合位于其绝对核心的Word2Vec算法与华育中学网络文化的结合。(当然,我只有来自于校群的数据,所以其实这更像是【校群2Vec】,毕竟校群里并没有所有的华育人,即便在校群里的大部分人也不怎么说话。)
在这两个月中,新增的工作主要在两个方向:一是在上游的,主要包括进行新的数据收集和处理;二是在下游的,主要关于探索用更新、更独特的方法、多角度的诠释和解读这些向量向我们揭示的的校群史内容。这第二个方向又能细分为三部分的工作:也就是我称为校群速通学、校群生物学和校群量化政治学的三个“学科”的创立。接下来我将分节演示Huayu2Vec小屋中的这些新内容。
二.溯回求之,道阻且跻
在《分析报告》中,我不无遗憾的在“结论与展望”中写道:“20年的数据丢失。目前在我询问的人中,没有人能提供2020年的记录数据。这非常可惜,因为其实相当一部分人最怀念的就是那时候的校群生态……”当时我对获取任何早于21年2月的校群数据几乎已经不抱希望了。
但是在文章发出之后,就有某清洁工在聊天区提出,他可以提供更早的记录,他的记录虽然比较残缺、但说明有些群友保存了更早的记录还是很可能的。于是我直接去联系了远在加拿大的群主路人甲(14668)。令我非常感动的是,他的确保存了自2020年2月16日第三校群建立以来,全部的聊天记录!(仅有少量缺憾)看着第三校群早期的种种再次浮出水面,校群友人无不感慨、怀念,回忆了更年轻时的故事。在整合了完整的路人甲卷轴之后,Huayu2Vec拥有了上至2020年2月16日,下达2022年5月28日的全部内容,共计108万行。(该txt文件有28.2MB之大)
更加令人惊讶的是21858的贡献。858是218时代的老人,在第一校群末期担任管理员。他成功的回收了一部分来自第一校群晚期的记录,这些记录起于2019年9月9日,结束于2019年12月23日,共计4万行。这份858卷轴忠实的反映了第一校群末期的校群风貌、对于研究近古校群史具有重大的史料价值。
由于规模较小并与占主体地位的第三校群记录异质性较大(那时校群还叫做‘华育学生营’),我并没有将其与第三校群记录进行合并,而是单独按照初步流程进行了分析,相应的一些结果我也会在下面展示。
在4月10日的0410导出之后,我又进行过两次主记录的导出和统计,分别是0509导出和0528导出。0509导出实际上在下文将要介绍的各种探索中发挥了不小的作用,但是就眼下而言,0528导出已经取代了0509导出在各种应用中的地位(其实中间差的几天,也不算很大的差距)。
我们将重走《分析报告》的流程,先运用正则表达式的方法匹配记录头,将QQ号和学号匹配起来,然后将QQ号连接起来形成伪句子,并交由Word2Vec算法进行嵌入。然后我将从嵌入降维可视化、词频和分布分析两个角度观察0509和0528导出,相关的详细流程和解释可以参考《分析报告》。
1.0509导出的嵌入降维可视化
在0509导出中,我采用了三种降维方法,除了原先的t-SNE和PCA降维、也使用了截断奇异值分解的降维方法,下面展示其中的t-SNE和截断奇异值分解图。
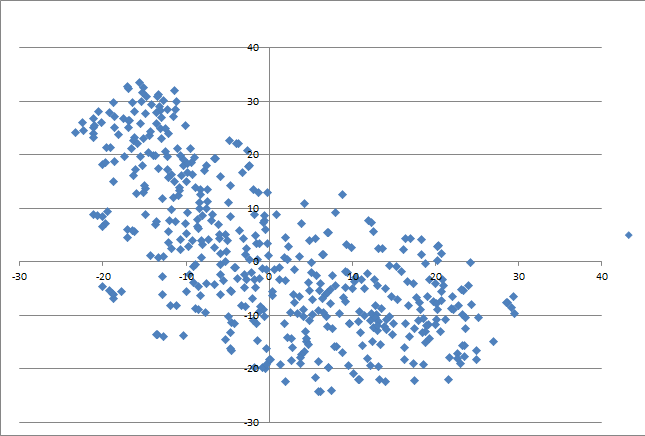
t-SNE降维图
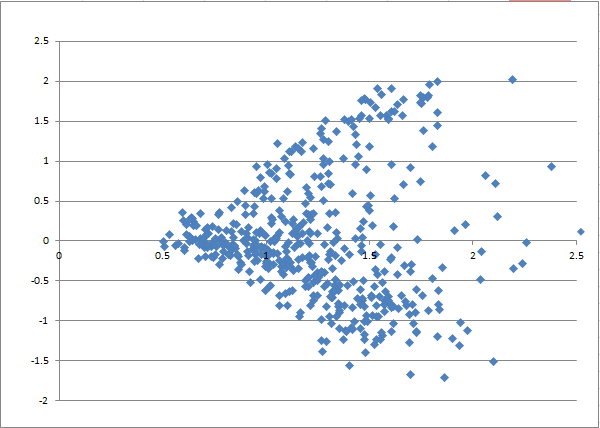
截断奇异值分解图
相较于0410导出,0509导出的点云无疑更加稠密。这是由于完整兼并了20年的记录所致:0509导出中有469个号出现,相较于0410中的231个号。0528导出中更是有479个号。
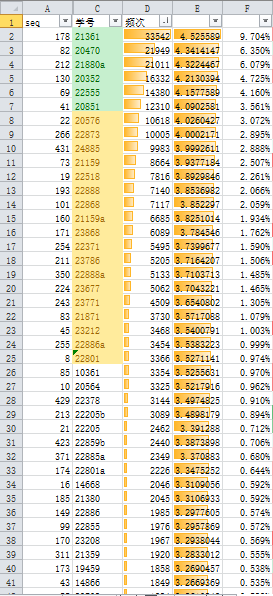
2.0528导出的词频和分布
0528导出中一共有345641条发言,其中发言频次最高的为21361,发言33542次、几乎占到整个第三校群史的9.704%,居于第二位的是20470,发言21949条、占到6.35%,第三位的是21880(a),发言21011条,占到6.079%。这三个人中,470和880都是第一校群衣冠南渡的元老。470在校群的发言在2020年之后就比较少了。而361则是后来居上,20年3月入群后,经过长时间的斗争,终于在校群中达到了巩固的地位。第三校群史的很多事件,很多就是在这三个人的互动中发端的。

同时也可以发现,在全部的第三校群记录中,21361发言频次的显著性,就不显得那么极端了,没有出现0410导出中“第一名是第二名两倍”的情况,而是被20年的全盛情况中和了。
以下是前0528导出中发言频次前80名的情况。在现在的Huayu2Vec中,我们解决了无法区别大小号的问题,但我们仍然保留了大小号的对立、没有将它们进行合并,而是用‘a’‘b’的附加字符标识小号。这里的小号并不一定是“发言较少”的号,而是指在记录中较晚出现的号。
颜色标识代表了依据布拉德富定律的三区划分,其中绿色代表“核心区”,黄色代表“相关区”,白色为“非相关区”,三区在总发言中所占的比重均为三分之一。(详见《分析报告》)显然比起基于0410的普查,也是均衡了不少。可见对于校群来说,20年的文化发展是多么的兴盛,比起后来21年的境况是多么的繁荣。
还有一些值得注意的点:
- 我们总是觉得群主路人甲很少很少才会出现并发言,但是他在第三校群仍然有超过2000条发言记录,应该也主要是在20年。
- 21380和21359在一般的“校群史”叙事中是基本不存在的,但他们仍然是校群的活跃参与者(2000条发言左右)。像这样的人其实实现了校群原本的目的(笑):为校友提供一个友好丰富的交流场所,而不是作为一个虚拟国式的政治斗争载体。那些更早期的学长一般也处于这种地位。
- 24513在导出之时正好具有1000条发言记录,非常巧合的。
- 直觉上来说,一个人在群里的“实际影响力”并不是和他发言数量直接线性相关的,而大概是和他发言数量的对数线性相关的。在上图中,发言数量左侧列出的就是对数发言频次,这些有3、4等级的人,基本上就是校群中的熟面孔了。
理论上我们也可以计算各时代校群发言频次分布的信息熵,用它来度量一段时间校群的“真实活力”。比如一段时间发言频次很多,但是事实上就两三个人一直在吹水,显然这发言频次反映不出此时群中实际上没什么活力。不过我还没来得及实现这一实验。
对发言频次的分布的讨论暂告一段落,现在我们来看看那三个“衍生学科”。
三.三个衍生学科
这一部分我会介绍一下基于Word2Vec数据实现的校群速通学、校群生物学和校群量化政治学。
1. 校群速通学
校群速通学是启发自B站上的“速通游戏”。其经典案例即“速通到‘世界最高城’理塘”该游戏的基本流程如下:
- 随机进入B站一个视频,一般通过随机数生成av号完成。
- 平台会提供该视频的若干推荐视频。点选其中一个并进入。
- 不断重复上一步,直到进入“到达世界最高城,理塘!”
这种游戏就是和此类企业部署的推荐算法进行的一种游戏,具有相当强的机器学习,甚至图论底色。抽象地来说,我们可以假想这个推荐算法内部的高维隐空间,其中每一个视频都是嵌入该空间的一个点。而速通者就像攀岩一样,不断从一个落脚点够到邻近的下一个,试图朝着固定的目标点移动。这也让人想起猿猴连续抓住藤蔓从而将自己摆荡到目的地的过程。
把握了速通游戏的精髓之后,它可以被推广到任何的‘2Vec’空间中,作为一种游戏性的高维空间探索。在H2V中,它主要基于“第三校群工具”(3rd_huayu_util)。它可以为群友寻找该模型下“最接近”的群友并报告相似度,并计算两个群友之间的相似度。(见《分析报告》)。只要稍加改动,我们就可以让该工具像一个推荐算法一样,对于每一位校友、从若干候选点中加权地抽取一些相关校友,并允许玩家从他们中选择。
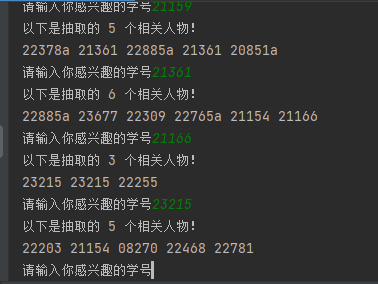
在实现中,我基于人物的发言频次和向量相似度两个因素分配抽取权重。一个人发言次数的对数频率越高、其嵌入向量与目标的预先相似度越高,则越容易出现。不过为了让发言较少的人也能出现,还有一个固定的平衡参数,保证所有人都有一定的权重。还有一个小机制,就是发言次数多的人也会展示更多的候选人物,让这些为人所知的活跃分子成为连接遥远地点的高速公路。
由于活跃校友自然没有B站上视频那么多,所以路径一般会设置的比较曲折,带有多个经停点。游戏的目标就是用尽可能少的迭代次数找到指定的校友。由于抽取机制,这样的过程显然有一定随机性。但对校群历史生态有所把握,肯定是有助于这一过程的。以下是一些案例:
1.22888->22873:
22888->20851->20352->22873
2.22765->24513:
22765->22555->22885a->22888b->24514->24885->22378->22859b->24513
(大概率可以优化,但懒得试了)
3.22880->23208(听起来离谱但其实不难)
22880->22372a(‘12253’)->23212->23208
4.21280->23677(更加离谱的)
21280->22105->22868->23677
(这条快速线路是刷了七八遍才找到的,理论上稳妥的方案是先进到212这些23届窝里,然后找23661、23670,但那太慢了)
多玩几次之后就会发现一些要领:
1.最大的障碍是时代。如果起始地和目的地都是当代的活跃人士,路肯定很近。相反,如果两个人中,一个是一位老学长,20年之后就没怎么说过话,另一位是刚进来一个月的学妹,这就很难找到一条通路(这和H2V的基本原理是密切相关的)。但还好有蘑菇、myj这样多年来持续活跃的人作为中转。
2.有一些难以摆脱的小社区,但是这些社区都有各自的边缘人物可供逃逸。例如:23届诸人形成的那个怪圈,一般利用23771逃逸(他还因为特别活跃,所以备选有5级,可以用作很多路线的中转):

3.有的时候是需要走回头路的。因为候选都是抽取的,所以一直刷一个人有的时候就能找到更好的备选。甚至有可能直接刷出目的地。
4.有的时候会有一些意想不到的联系,这很正常,毕竟H2V唯一的判定标准就是发言接续,和现实交往是有很大差别的。
总体来说这个游戏还是非常有趣的。由于这个游戏中距离的度量方式不是欧式距离而是余弦距离,所以拿着一张余弦空间中的tsne降维地图将会是非常有利的:
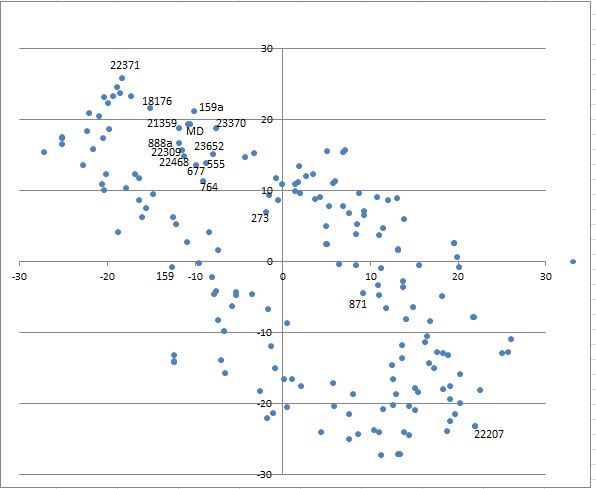
下面让我们来看一下基于分类的“校群生物学”。
2. 校群生物学
校群生物学是脱胎于《分析报告》后半部分中,采用K-means等方法进行聚类的尝试。这里的“生物学”其实指的不是“Biology”,而更像“Taxonomy”,也就是林奈的工作:科学的对物种进行分类。“校群生物学”的称呼和形sh式是启发自22885的“阵面对战生物学。”阵面对战是一种卡牌游戏,其中的卡牌各有特性和作用,885先生依据这些属性对它们进行归纳,总结出了此节:
校群中活跃校友的数量,比阵面对战中卡牌的数量还要多一些,但是我们也可以对H2V嵌入进行这样的归类。这里用到的工具属于“Hierachical Clustering”,即层次聚类。层次聚类有两种形式,一种是自上而下的“划分”型,如Hierachical K-means,就是不断的在不同层次上进行K-means聚类。还有一种是自下而上的“聚集”型,即Agglomerative Clustering,也就是我们此处采用的一种。
在AC中,距离最近的两个节点会首先被合并为一类,然后随着我们逐渐调大筛选孔径,相近的类别会不断被合并,最终所有的类别被合并为一类,这时就出现了一颗层次聚类树。在合并的方式上还有一些细节:比如,是必须两个类别中所有点的距离都已经小于筛孔,才予以合并,还是两个类别点的平均距离小于筛孔即可?这两者分别称为“complete linkage”和“average linkage”,还有一种更优化的“ward linkage”可用。也就是我们所采用的方法。
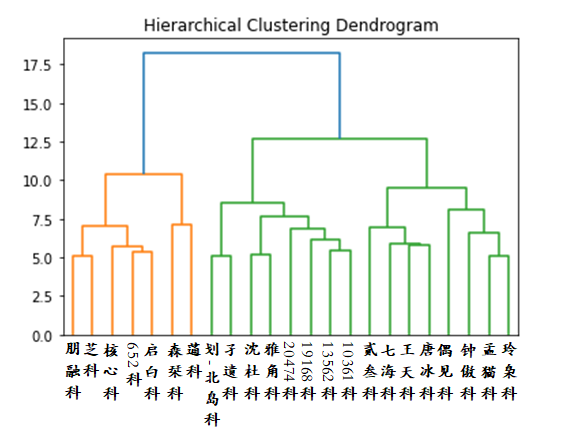
这是我们画出的聚类图,孔径大概取欧氏距离15为“门”,9为“纲”,7为“目”,5为“科”,科下又以3.6为孔径设“属”,但数目由于过于繁多就不命名了,上面的树状图也是只画到科的粒度。而归类图则是模仿阵面对战里的做法绘制,表现了校群归类的形态。在完成了整体上的分类之后,我不厌其烦的将具体的门纲目科属种和具体的人对齐在一起,并为每个科取了一个名字。不过这些名字很难做到恰如其分:这些类别的划分有的时候相当不可解释。

在校群生物学中,校友发言的频次被戏称为“种群数量”。
比较有趣的几点包括:
- 大类明显和时代相关,与校群速通学中的结论一致。
- 最核心的校群人物都被集中到一个科:“核心科”中,这是令人感到惊讶的。但他们确实有共同特征:发言贯穿了第三校群所有的时代,这也就是聚类的依据。根据之前的粗略统计,近新门的种群大小占到全校群种群大小的60%多,而核心科一科又占到全近新门的超过50%,可见核心科的巨大影响力。
- 与之相反的,非活跃校友也被非常随意的扔到了近古门古核心纲下的“偶见目偶见科”。这也是由于H2V的机制,只有一两次发言的人嵌入是非常欠训练的,因此在校群中心较为聚集。
- 20470和22873在同一个科。
- “类学联目”。学联是微信的校群,很多主要在学联活动的人在校群也聚在一起。
- “贰叁科”。这个最为神奇,很多23届的核心人物,尤其是那些20年暑假参与了所谓“23届战争”的人物都被归入了此大类。可见他们是校群活动,是共进共退的,令人感慨。这一点和速通学中“23届小圈”的困扰遥相呼应。
校群生物学的具体内容,我已经整理好并以一份《【Huayu2Vec工程】校群分类学指南发布版》的形式公之于众了,有兴趣的校友可以去看。不过随着校群的继续发展,校友嵌入还会继续发生变化,新的人物也会出现,那么该分类也有可能日后出现(甚至相当剧烈)的变化。以上的聚类是基于0509导出的。当我用仅仅两周后的0528导出运行层次聚类时,很多变化就发生了,比如核心科被拆散,23702被画出23科并随着22372等人与孟猫科合流(还有什么22765之类的,导致新孟猫科完全起不出名字)。
校群生物学有的时候也能对速通学产生指导作用,他能指示小窝的存在,不过不能完全指示通路。
最后让我们来看看最特别的一个:校群量化政治学。
3. 校群量化政治学
校群量化政治学不直接称之为“政治学”,主要是因为校群政治学早就存在了。当人们开始为群管选举争论不休时,很多校群政治的概念便出现了。而基于H2V数据给出的量化鉴定,则是一个新的方向。
目前我也没来得及在这一块做出更多的探索,所以先介绍一下数据吧。
校群量化政治学不同于之前的两个H2V衍生物,它是需要补充额外数据的,不止采用发言接续。这额外数据就是第三校群历次的选举数据。(第一校群估计进行过更多的选举,但无法回收了。对今天的研究也影响不大。)这些数据由于在群内置的机制内部,都是由我和22888手动录入csv的,这项工作就花费了整整两天。最后的结果是一个庞大的二值表格,以参与过校群投票的校友为行向量,以每次投票的候选人作为列向量。同一个人多次参加选举,视为独立(不相关)的两次数据。这样就生成了一个校友的校群政治表征,其特征维度为每一次校群选举的各个候选人。
比如,873-210705就是21年暑假选举中22873候选人对应的向量。如果一人为他投下了一票,那么那个人的行与该列的交点处就要点上一个1。等所有1都点完,则其余候选人则未被选择,全部赋0。如果一个人最后发现完全没参与某次选举,原则上留空,不为其赋1或0,这是因为有些机器学习算法对缺失值有特别的处理方法。但在目前我用的处理方法中,最后还是会为缺失值都填上0。
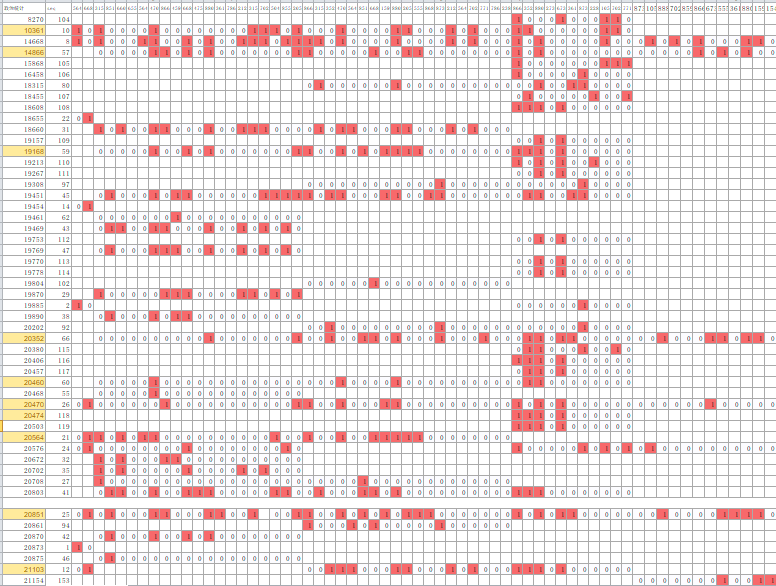
数据录入示意图。
最后总共157个校友参加过管理选举。这个数字是我们始料未及的,因为H2V中活跃过的校友也就这么多。
有了该数据之后,我们还是先试试用无监督的方式对它进行降维和阐释,毕竟它现在出于一个芜杂而高维的状态。由于数据多为二值,我决定先采用一种较少用的“深度信念网络”算法(Deep Belief Network,DBN)。这种深度学习算法的原理对我而言比较晦涩,其大致原理如下:
DBN可以有若干层,每一层有若干隐节点,与一般神经网络相似。但是传统DBN的每一个隐节点状态都必须是二值的,非1即0(应该是用sigmoid函数之后四舍五入)。相邻两层之间,DBN执行全连接。
DBN的每一层都是一个受限玻尔兹曼机,训练时逐层训练,而不是像一般神经网络一样总体训练。受限玻尔兹曼机(Restricted Boltzmann Machine, RBM)的原理大概是模拟一个热平衡的过程,让能量在节点之间流动,并最终使上下两层节点之间可以互相表征。它的损失函数也因此被称为能量函数。
因此DBN的表现是类似一个无监督的二值自编码器的,我们可以用它来生成一些二值数据的简约表征。这个过程据说有个诗意的名字:“做梦”。这是因为DBN表征有很强的任意性,仿佛是从数据中“梦到”的一样。

DBN以及训练过程。
最后简约化的投票数据效果如下:
左侧为第三校群四次投票的原始投票数据,右侧16列为DBN给出的隐分类。
这些隐分类也是比较不可解的,所以必须想方法进一步降维。我采用了PCA对DBN未二值化的原始输出进行降维,取两个主成分:
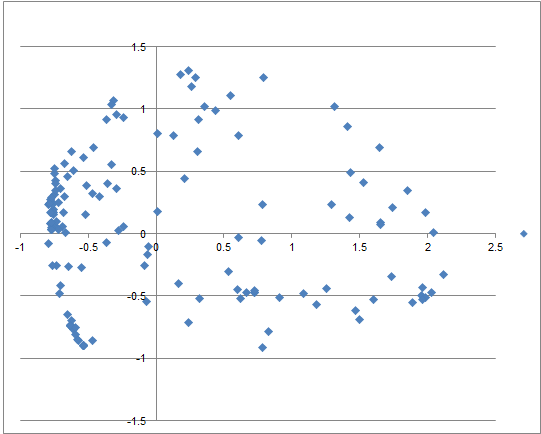
可以发现第一个最主要的主成分对整体数据的诠释能力就已经颇为强了。第二个主成分显得比主成分方差少很多。
那么,当我们把这个主成分和具体的人对应起来的时候,它能告诉我们什么呢?
答案有些令人出乎意料:这个值似乎和一个人是否属于“里站”(一个历史悠久的,一些活跃校群人组成的小群)有很强的相关性。


稍微把表格往下翻一下,就会发现没有那么多“里站”人了。观察16个隐分类,也发现里站人被“点亮”的类别相对更多。我对此的解释是这样的:里站人以前一直是参与校群活动最积极的那批人,一次不拉的,完全按照规定的进行投票的也以他们为多。不仅如此,他们所做出的候选人的选择,也是较为一致的,因为很多里站人自身也就充当候选人。是参与校群选举的积极程度决定了该参数,而里站性也与这个积极性相关,造成了总体的相关性。比如20474、20460,他们虽然是里站人,但在校群活动少,参与投票不积极,因此“里站程度”是比较低的。
所以这个指标或许改叫“参政积极度”比较好?也不尽然。因为参政积极度不该这样反映,而是可以直接统计参加了几次投票即可。因此出于好玩我还是称之为“里站度”。
以下列出几个比较著名的非“里站”人的“里站度”,仅供娱乐。(此处是进行极差变换后的里站度,在0-1区间)
| 学号 | “里站度” | 学号 | “里站度” |
| 14668 | 0.974 | 21361 | 0.543 |
| 22315 | 0.954 | 22765 | 0.545 |
| 22888 | 0.910 | 22801 | 0.585 |
| 23212(702) | 0.841(0.838) | 22518 | 0.521 |
| 23564 | 0.177 | 22873 | 0.334 |
| 23771 | 0.480 | 22372 | 0.354 |
注:里站度的平均数为0.273,中位数只有0.118左右。
到目前为止,该方向其实完全没涉及到H2V。但纯粹出于好奇,我准备看看“里站性”,即“DBN给出的校群投票特征嵌入的主成分”是否能从H2V嵌入导出。于是我将H2V嵌入与此处的嵌入对齐,如果人有小号也统一对齐到同一个向量。
随后,我先试了试sklearn提供的线性回归,在训练集上只能实现0.47的确定度(1-方误差/方差),可谓相当糟糕。在测试集上更是以-0.09的水平,比一个只会输出预测值平均数的常数模型还要差。这还是在我从学号导出“届数”作为一个数值特征添加到了嵌入末尾的情况下。随机森林回归器在测试集上也只能打到0.2左右。效果最好的是ExtraTreesRegressor,在测试集上能有0.3确定度。可见发言交互嵌入不能准确反映一个人在校群政治中的选择。这就是校群量化政治学的启示。
不过这个回归我也集成到了“第三校群工具”,就当看个乐呵吧。
校群量化政治学仍然有不少发展空间。目前这个预测只是针对单独的一个宏观指标,但是对各个特征没有兼顾。同时这只是针对选民画像的研究,没有对候选人进行量化表示。这个方向也应该和H2V本体建立更多有益的联系。这些都可能是暑假里进一步探索的方向。
四.总结
这个报告,像上一个一样,已经耗费我过分多的时间了。但是对于任何科学研究,以一种合理的方式呈现并与同行交流,与得出研究结果是一样重要的,这也的确是正式的“科学流程”的一个部分(就是什么提出问题-形成假设之类的)。
上述三个方向一个是游戏性的,一个是脱胎于聚类方向的描述性统计,最后一个是主要基于投票数据的校友归类。三者各有侧重,但都是H2V项目中有趣的实践。校群数据集仍然有许多宝藏等待我们发掘,这是毋庸置疑的。
在H2V之外,我之前也用现成的GPT-2 chitchat模型训练了一个基于校群聊天记录的聊天机器人。这个基于注意力的语言生成模型具有八亿一千万参数,模型大小有300mb之多(我不得不在OpenBayes算力平台上租赁虚拟GPU并用四个小时训练完成),但是最后的效果并不令人满意:它完全没有“对话”的感觉,而只会莫名其妙的吐出一些词句,只是偶尔能因为引用了一些校群人物或者梗而使人惊呼或发笑。可见校群聊天记录在完成清洗后有9mb左右,训练这样一个对话机器人显然是不够的。其质量也不敢恭维,因为天知道校群人聊的各学科的专业知识,各游戏的各种操作,还有那些魔怔的,本身就近乎乱码的话语,在我不精的清洗下,会给机器人带来什么影响。这个机器人我也在校群演示了,更多样品我可能会专开一篇文章来讲述。
非常搞笑的一点是:我写这篇文章写到一半的时候,第三校群也莫名的陨落了,不可谓不讽刺。我这些数据变成了描述第三校群最后的,也是几乎唯一的资料了。我们晚一天,就连投票数据也得不到了。以后我就不得不开始采集“第四校群数据”了,并开发“第四校群工具”,但一般来说我还是会把他和第三校群的东西拼合在一起的。
第四校群由我本人完成重建,而由于路人甲忙于自己的事物,授权我代行其位。因此你们校群忠诚的史官和数据分析技术员,也成为了校群的摄政王。有趣味性的。
新群号是729672267。
21159
2022年6月19日于上海。
上一篇H2V文章(即《分析报告》):https://blog.nth.ink/others/P4378.html
关于作者旅菇佘侨159
- 退学,成群结队,连连骂
- Email: jiazhibai@hsefz.cn
- 注册于: 2022-05-25 00:14:29
科学的,高级的,复杂的,引人深思的
现在看两年前预初的时候23届这圈真的挺有意思……但现在除了771基本无一例外都隐退了
我的感觉是两轮疫情和网课会让这些数据变得有意思的多,每一届都有不同的情况
@23 786 经过更多实证,23868其实也是一个不错的逃逸口,因为他的备选可以直接刷出20470和22873……当然他和771侧重点是不一样的,他是偏向古核心纲-古核心目-孟猫科的,771偏向蘑达,也就是核心目-核心科。理论上还有23212->22801a也是出圈的,但这条线是一路往古代走的,而且比较“细”(备选不多)。