
本文作者:旅菇佘侨159
本文分类:Huayu2Vec工程 计算机技术 浏览:1623
阅读时间:12366字, 约13.5-20.5分钟
.jpg)
、
摘要
本文在对QQ群聊的格式化聊天记录进行清洗后,采用Word2Vec算法对群友发言接续进行嵌入,以求得不同群友交互的模式。通过这些嵌入向量,我们得以了解群友之间的关联性,并对他们的共现情况进行了可视化。本文同时对群中发言频率的统计分布展开了调查,使用文献统计中Zipf定律和布拉德福定律进行了拟合。本文还使用了K-means算法对群友的交互向量进行无监督聚类,探索华育校友营中是否形成了一些小团体。最后,在嵌入信息的基础上,开发了判断人物相似度、寻找紧邻的下游应用,作为一个有趣的小工具。
一.算法与数据
机器学习已在模式识别领域取得了很大的成果。几乎任何形式的数据都可以交由这些算法进行数据分析和模式挖掘。在自然语言处理算法中,Word2Vec的泛用性非常强。几乎任何自然语料,各类离散信号、离散序列、乃至图模型等都可由其求得嵌入。
Word2Vec是一种统计语言模型,也属于神经网络模型。它非常轻量,仅包含输入层、隐藏层、输出层三层。其中,输入层一般用词汇的独热表示(One-hot representation),即向量的维数和词汇量的大小等同,仅把词汇对应的一个维度设为1其余均为0的一种稀疏表示。
其原理包括两种:一种称为CBOW,训练目标是使用语境预测中心词,一种称为Skip-gram,目标是使用中心词预测语境。语境是指中心词前后的若干词汇。所谓预测,其实也就是分类的工作。某种程度上它也能作为一个生成模型使用,能完成类似完型填空的阅读理解任务,不过受制于其只考虑局部信息不能利用全局信息,以及只考虑共现不考虑词汇顺序的局限性,人们现在一般只用它求解嵌入向量,再交给如LSTM这样的下游算法去深入。所谓嵌入向量,其实就是指每个词汇输入网络后生成的隐层参数。
本文使用Word2Vec就并不是针对聊天内容本身(因而不是一个NLP任务),而是发言接序。具体而言,每一个群友(以QQ号为标识)都可以抽象成一个“词汇”,群友相连的聊天顺序则被转化为“句子”进行训练。经常在短距离上共现的群友,说明经常在一起聊天,其嵌入向量越相似。反之,如果两个群友对彼此的发言从来不感兴趣,就不容易在聊天记录中共现,嵌入向量就越疏远。
本文采取的数据是使用QQ消息管理器导出的该群聊天记录,以txt形式保存。文件包含从2021年1月28日至2022年4月10日的所有记录,总计约24万行,包含至少8万条发言。
二.分析流程和代码
Ⅰ.数据清洗与嵌入求得
由于QQ聊天记录的高度格式化,可以较容易的用正则表达式对各类数据进行匹配。


qq = re.search(r'(?<=[(<])[^)>]+', head).group() #提取QQ号的正则表达式由于群规定强制成员在昵称前添加学号,这一部分也进行了匹配,并用字典与QQ号进行了对齐。这有助于后续的可视化。
Word2Vec算法直接采用from gensim.models import Word2Vec引入。由于它接受的训练语料形式是句子的列表,程序也将把聊天接续整理成句子的形式。具体而言,QQ号以字符串形式直接形成一串,但按天为单位断开,每天的接序单独形成一个。这意味着如果两个人在半夜聊天,他们的序列会被分装进两个“句子”。不过,这无伤大雅,本来这种情况也不多。
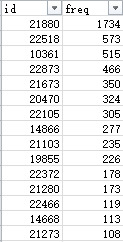
同时,程序进行了发言频数统计。这一数据对于后续的处理意义是很大的。
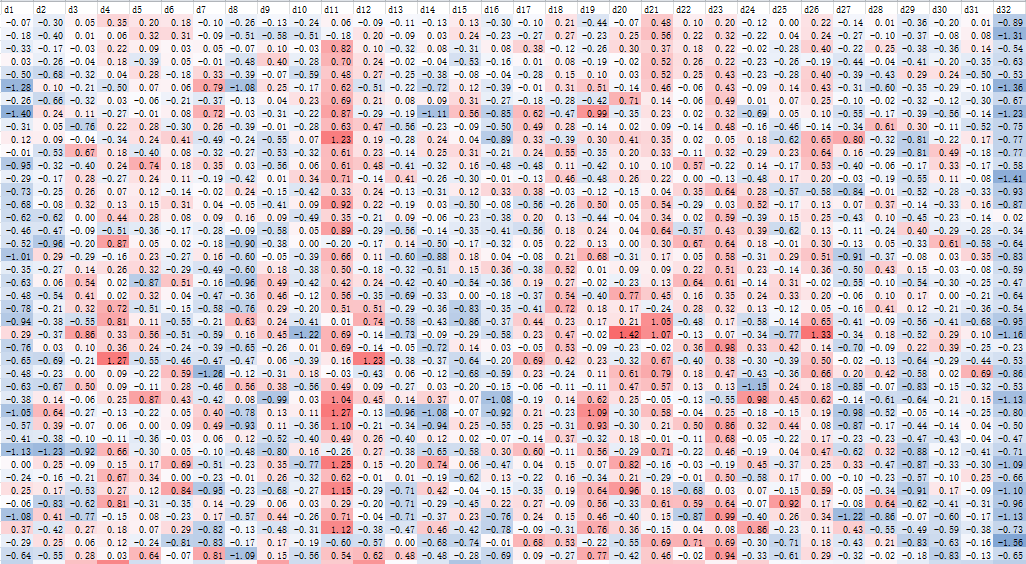
训练得出的嵌入设为32维,因为“词汇”量并不是很大,只有231个人。发言频数、QQ号与学号的对照等都导出到了txt,方便后续直接调取,以及转移到Excel进行可视化。(Matplotlib比较重型,没有那么灵活,以后可能会用。)
有趣的是,Word2Vec输出的向量表天然就是按照词频排布的。可以看出,越是高词频的嵌入,特征越鲜明,各维度上偏离零点的程度就越大。反之,只发言过一两次的人,没有得到很充分的训练,向量很接近于零向量。

Ⅱ.嵌入降维
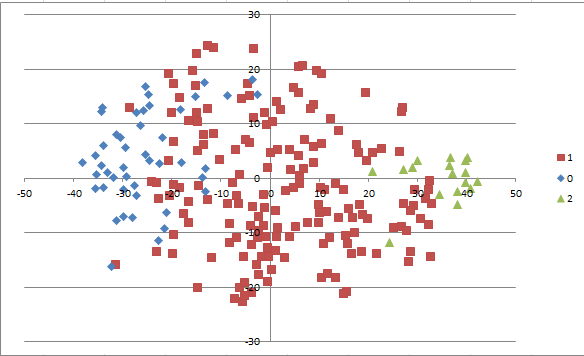
对32维原始嵌入进行t-SNE降维和PCA降维(来自sklearn库),效果如下:
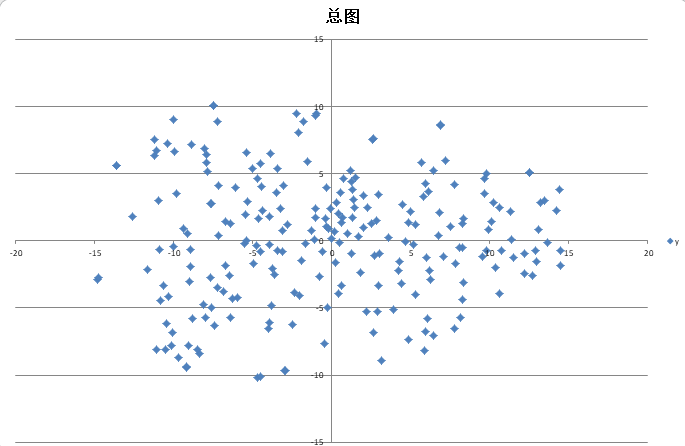
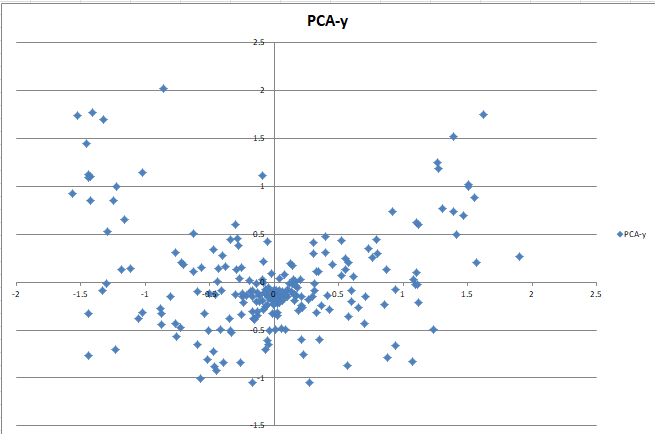
可以看出,在两种降维方法中都有相当数量的点聚集在原点附近,这些就是不太发言因而没有特征的群友。特色明显的群友则会发散到“星团”的边缘。因此,我在后面选取了前55名发言最多的群友,制作了更精细的一张图来进行分析。
Ⅲ.词频和分布分析
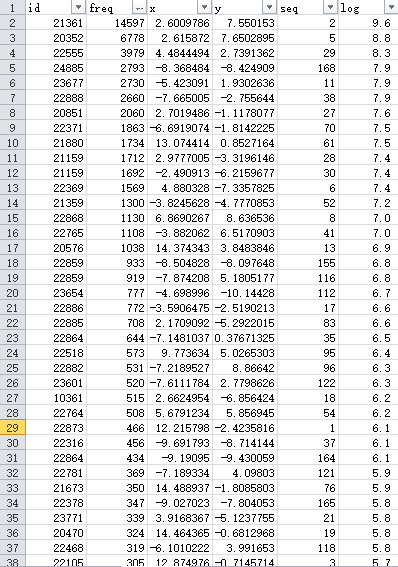
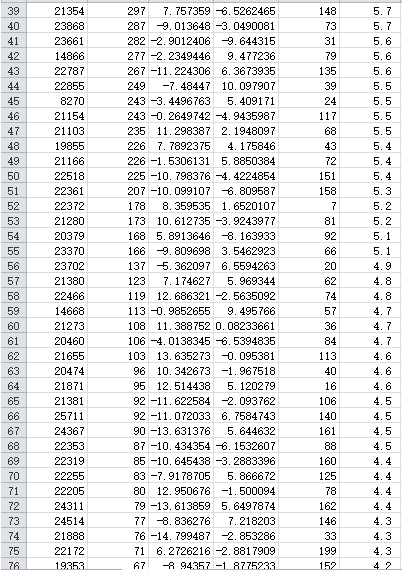
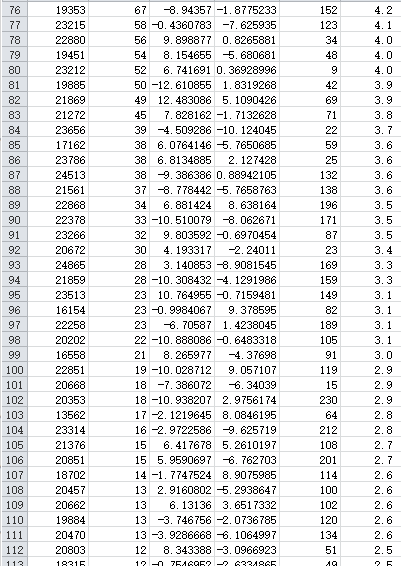
有趣的是,发言频数按照降序排列时,似乎和Word2Vec设计上要处理的自然语料同样,是遵循幂律分布的(又称Zipf分布)。
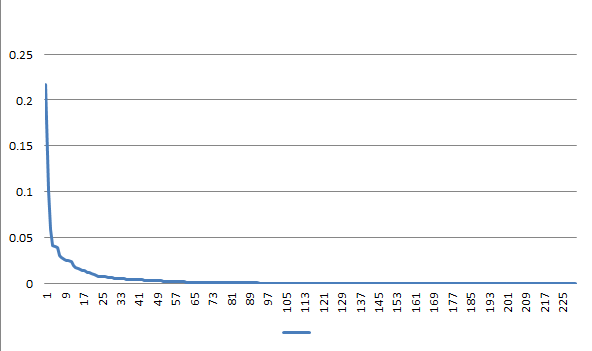

这是一条文献统计学中的经验定律,表现为语料中的词汇按词频降序排列时,词频与词汇的排名呈反比关系。其形式化表述为:

在自然语言中,C约等于0.1,alpha约等于1。在本数据上得到C=12.64,alpha=2.42
幂律分布在非常多涉及到任何信息的场景下涌现。比如,音乐和机器码中排列的分布、互联网网站数量和访问比例、人们的收入、甚至经济系统中偶然波动的幅度等等。关于这个奇妙的定律历来有很多解读,有人认为在信息熵和词汇集大小的矛盾中,该分布会作为效率最高的基态自然出现。这个分布还有一个进阶版的Zipf-Mandlebrot版本,给r添加了一个偏置项k,据说拟合效果更好。
(不过经过实际拟合,这个数据可能更接近指数分布而非幂律分布,尽管两种拟合均显示为具有显著性。)
同时我也验证了在该数据上是否存在布拉德福定律。这也是文献统计的一个经验定律:如果将科技期刊按其刊载某学科专业论文的数量多少,以递减顺序排列,那么可以把期刊分为专门面对这个学科的核心区、相关区和非相关区。各个区的文章数量相等,此时核心区、相关区,非相关区期刊数量成1:n:n^2的关系。
在该数据上,前2名群友发言计21375条,后9名发言计21223条,再后面的44名计21340条,表现出布拉德福定律的特征(n约等于。这里只从顶部开始统计了95%的发言,因为如果对100%的发言进行统计,倒数的218个人的发言加起来都占不到所有发言的1/3……整个群的“核心区”可能的确就2个人。
关于发言频数分布的讨论暂时告一段落。下面我们继续对发言接序的嵌入进行观察。
Ⅳ.降维图上的可视化分析

在这张图中揭示了一些有趣的关系。比如:
1.361和352是两位在群里非常喜欢互相辩论的人士,在大量的记录中都是邻接的。因而两个点紧密贴在了一起。(事实上,他们两人就是发言最多的“核心区”,可以观察上面原始嵌入的前两行,就会发现十分相似。)
2.有小号的人,他的小号和大号会表现出较大的距离。我推测这是因为大号和小号本身是很少会同时出现的,因此即便这个人物用大号和小号和相同的人交流,模型也会试图拉大大小号的距离。
3.第三象限形成了一个含有6个活跃人的小聚落。
4.x轴正半轴高处产生了包含21880、20470和21673的一个小聚落。
5.22555周围非常空旷,离最近的活跃人都很远。有人调侃道:”555的聊天习惯过于诡异。"当然,如果看总图的话,可以认为这个点受到了来自中央非活跃“暗物质”的吸引,说明555的聊天实际上是比较平均,和各种人群都有交流,因而靠近中心。
6.这张图上228诸人之间的联系没有想象中强。在更早一版的pilot test中(只采用了部分记录),228的四个人(882、864等)集中的显现,形成了聚落。在主成分分析降维图上,859和864也是挤在一起的两个点。

不过关于这个假设,确实有很多值得推敲的点。228虽然活跃人数众多,但其意识确实不像更早的218诸人那样统一,也没有出现“校群当班群用”的情况,而更像一种百花齐放,每个人有各自的性格和关注点。尤其是888、885、886这些,交往范围不限于同班人士。
如果我们可以取得2020年以降的所有记录,然后从中观察218大行其道时代的现象,我们可以预期218人士在降维图上更紧密的聚集,或许是紧密的团结在如803、806、871这样的高活跃成员周围。他们也经常连在一起刷斜眼笑,这会增加数据的绑定程度。
当然,大体来说,同班同学之间确实会更加靠近。参考223-、227-、236-。
7.21166很意外的上了榜,尽管他只是偶尔来刷个“早”的那种人。类似的非对话行为其实对数据的确有一定干扰,对于活跃性本身较低的人尤其如此。不过,非对话行为也不一定是随机的,有的时候一些潜水人只是等待着好友出现,然后冒个泡表示存在。

8.22787似乎位置非常偏远,远离最活跃的头部以及中央的非活跃大部队。实际上他确实也不太与群人士的主流交往,和他关系最密切的那些人很有可能在这张图上被隐去了。i.e.他的位置也来自于“暗物质交互”。也可以认为他是一个非活跃小社群唯一在数据上活跃的代表。在另一侧的20576也表现出类似的偏远,其原因应该也类似。
9.对于整体上的分布,似乎存在这样的规律:2020年及更早就开始活跃的老校群人士大多出现在右侧,而2020年、2021年以后涌现的后辈则多居于左侧。这样一种“左右翼”的既视感颇有“长江后浪推前浪”的意味。(在后文的聚类中,会多次讨论这种情况,并为具体的集合赋予术语。)
10.相关区整体是在活跃环的内侧,这一点或许反应了多说话就会更多受随机交叉的影响,向中心靠拢。
Ⅴ.无监督聚类与分析
在观察完分布的大致情况之后,我决定进一步采用K-means算法对嵌入进行无监督聚类,以求进一步探索数据的先验规律。这里有一个研究假设,就是校群中形成了不少“小团体”。这一假设是22873首先提出。

在第一波的分析中,全部的数据都使用了,没有排除低频数据。聚类的数目我取了一多一少,分别是n=3和n=8。


这两张总图所用的参数和之前带标注的图是一致的。可以看出降维之后、不同的类别之间其实存在着大量的交叠,信息损失略大。我认为这或许是t-SNE算法中困惑度参数perplexity取得太大了(25),而数据本身没有那么复杂。一般而言,困惑度取高会让最后的表征更关注整体性的、宏观的结构,取低会使它更关注局部性的、微观的结构。因此,为更好的展示聚类的成果,我重新运行了t-SNE算法,这次取perplexity=10。
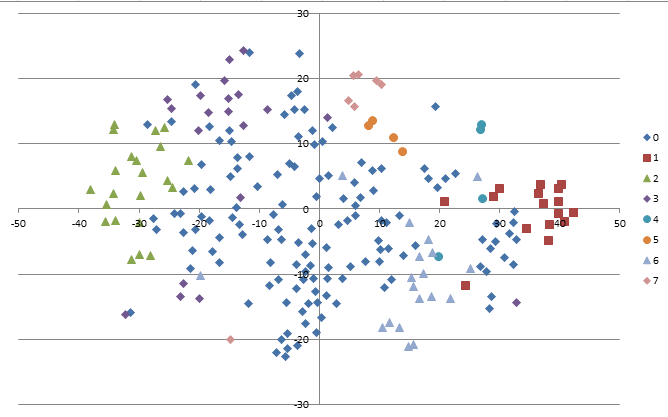
可见可视化效果好了不少。不过要注意到这张图和上一张图相比,“左右颠倒了”,原先在最左侧的人这次被投影到了右侧、反之亦然。
在两种划分中,少特征的不活跃人、连带一部分活跃人都被集中进了中心的一个大类,而两端分离出去形成两个小群。其中0类有46人(以21880、22873为代表,占19.9%)、有6638条记录(占9.8%),2类有17人(以24885、22859为代表,占7.3%)、6022条记录(占9%)。最大一类1类有168人(以21361、20352为代表,占72.7%)、54580条记录(占81.2%)。

三类的代表人物如上。
在8类划分中,最大的一类0类(原1类)把原先0类中一部分靠近中心的点吞并,但它又在边缘上释放出3、4、5、6、7五个小类,因此下降为135人、35850条记录。
接下来对分为8类之后分离出的那些小类加以观察。
新1类与原2类基本重合,只有一个人(22319)被划入新4类,因此可以直接参照原2类讨论。
新2类完全来自原0类,只有22518、10361、19885这三个显著人物分离出去并入新3类。
新1、2类可以与上文可视化分析中“左右翼”的既视感相照应,大致勾勒出“新人”、“老人”的边界。
新3类除了包含来自原0类的一些人,也包含原1类(最大类)中分流出的20352、22369、22764、23771。有趣的是,20352和21361分野了,这是非常出乎意料的一件事,考虑到他们的嵌入向量如此相似。22868也和自己的小号分在了两类,即便在图上非常靠近。当然,K-means是有一定随机性的,或许有所干扰。
意外的分列
新4类新5类分别只有4个和4个人,521条和、1209条记录,分别以22787和23601为代表。它们从原先的最大类1类分出。在降维图上,它们表现得相当分散,即便人数非常少。这种类的出现一般说明类别n选取过大……
高度分散和微小的新4、5类
新6类具有较大显著性和现实意义,它是可以某种程度上代表228的大类。它从原最大类分出,有19成员和5960条记录,规模可以媲美原0、2类。引人注目的是其领衔的5个人物、分别是22888、22859、22886、22882、22855,均为228-人士(虽然新2类也有)。25711也在这个类中是比较有趣的现象。
新6类构成
新7类有6个成员和1787条记录,以23654和22864为代表,完全由一些22、23人士构成(包括23661、23656等)。这个22864应该是小号,他的另一个号是和22859的一个号贴在一起的,都在新1类。由于我本人对这一类的人物不太熟悉,也不宜做出更多评述。
由于这两次聚类使用的材料都包含所有的人物嵌入,所以那些欠训练的非活跃“暗物质”也会以同等权重参与聚类(我并没有使用带权K-means)。尽管这些嵌入大多因为靠近中央而被吸收进最大类,我仍然怀疑它们会对活跃人物的归类产生一些意外影响。因此,在第三次尝试中,我以50条记录为界,先将该阈值之下的人物统一归入“不活跃”大类,然后对剩余的80个人进行了一次分为3类的K-means聚类。以下是总图:

t-SNE图,其中3代表不活跃类
这样处理形成的三类,和原先的三类存在较大的不同。新的聚类更明确的勾勒出了活跃人群中存在2-旧系(“里站-二百猫”系):0-群主体(361-352系):1-新系(24885-228系)的分立,显示了它们的相对关系。三系的人员组成及发言占比展示如下(饼图不按比例):
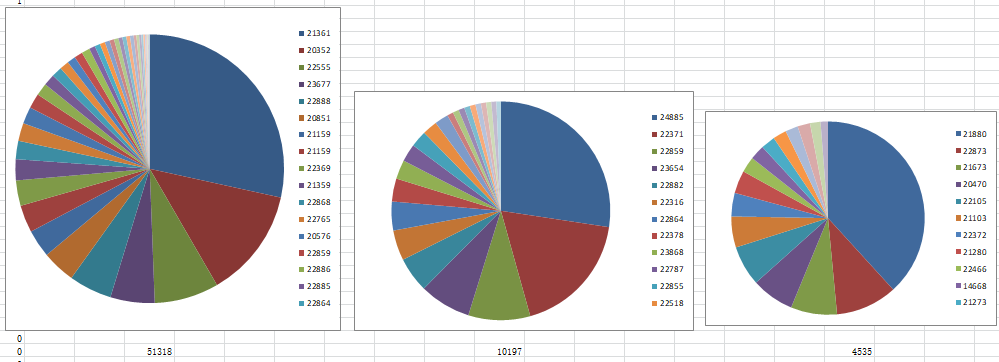
可以看出每一类的饼图中都形成了螺壳式的幂律排布
构成旧系的就主要是21-的一些旧群友,他们的数据也更有历史性,主要来自于21年。构成新系的人员数据则相对后起,这两系的不共现促使了两个异质类的生成。主体系的共性就是他们在整个时间轴上都有分布,造就了他们居中的地位。
三系模型反映了21年-22年间校群发生的转型:从主体系+旧系的活跃组成过渡到主体系+新系活跃组成。
这个三系与之前分析的新8类之间的对应非常复杂,难以得出合适的结论。基本上每一个类都包含着新三系中各个系的一些人(而且有的交叉是很奇怪的,比如远古的21655被归入含20352的新3类)。在结合实际比较之后,我认为还是新三系模型对群中的情况更有诠释力,只是不包含所有的人物而已。
所以回到873提出的假设:我认为校群中确实形成了一些小团体,但这是很自然的一种现象,主要受到现实生活中的交往关系制约。873自己也是旧系的一个成员:他在21年暑假之后再也没有在校群出现过。
最后附上用于降维、聚类的主要代码(其实也就是最基础的调用)
def transform(embeddings):
emb_list = []
for k in qqs:
emb_list.append(embeddings[k])
emb_list = np.array(emb_list)
down = TSNE(n_components=2, learning_rate=300, init='pca', perplexity=10)
#down = PCA(n_components=2)
node_pos = down.fit_transform(emb_list)
def cluster(embeddings):
emb_list = []
for k in qqs:
if qq2freq[k] >= 50: #筛除不活跃成员
emb_list.append(embeddings[k])
emb_list = np.array(emb_list)
object_cluster = KMeans(n_clusters=3, random_state=0)
object_cluster.fit(emb_list)
y_pred = object_cluster.labels_ # 获取训练后对象的每个样本的标签
#centroid = object_cluster.cluster_centers_
pred_key = 0
for k in qqs:
if qq2freq[k] >= 50:
qq2cluster[k] = y_pred[pred_key]
pred_key += 1
else:
qq2cluster[k] = 3
三.下游开发与应用
机器学习本身往往是一种极其宏大的叙事,它站在指挥台上观摩数据的阅兵,它如同俯瞰蚁穴一样审视着一个个同质的点的运行,得出的规律也站在无比的统计学高度之上。
但对于本研究这样以人为本的观测,还是有必要还原出微观的视角,为每一个群友提供更加个性的评价,发现一些容易在俯视时忽略的细节。
因此,在之前训练好的模型之上,我开发了一个下游应用“第三校群工具”(3rd_huayu_util)。它可以为群友寻找该模型下“最接近”的群友并报告相似度,并计算两个群友之间的相似度。
其原理非常简单:Word2Vec模型中本来就提供寻找近义词和计算词汇向量余弦相似度的函数,在本研究的语境下调用这两个成员函数就可以实现上述效果。以下是代码:(同样,为了防止欠拟合向量的干扰,算法不会匹配非活跃学号,但是还是允许为不活跃学号查询相似)
def near_model(temp_id):
if sid2qq.__contains__(temp_id):
near_list = model.wv.most_similar(sid2qq[temp_id], topn=40)
print("以下是和该学号关系最密切的5活跃人物和相似度!")
count = 0
i = 0
while count < 5 and i < 40:
if qq2freq[near_list[i][0]] >= 50:
print(qq2school_id[near_list[i][0]], end=' ')
print(near_list[i][1])
count += 1
i += 1
输入和输出都是”学号“、但内部还是采用qq号作为唯一的对齐标识,中间用字典转换。这有一个美中不足的地方,就是当存在小号的时候,模型只能匹配其中一个号、而且无法预知匹配的是哪个号。这在以后可以通过添加额外的标识解决。
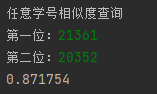
while school_id != 'exit':
print('任意学号相似度查询')
school_id = input('第一位:')
temp_school_id = input('第二位:')
print(model.wv.similarity(sid2qq[school_id], sid2qq[temp_school_id]))

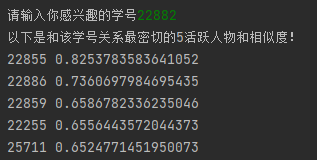
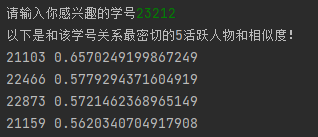
最近邻学号检测(注:21810在当前所有的记录中只有一条,当时可能正好这几个人在聊天)
这些工具在4月11日、12日已在校群公开演示,反响不错。
对于本分析中产生的原始数据和聚类、降维得出的数据、源代码等,我将会在做出妥当的处理(保护隐私)后予以开源。
四.结论与展望
Word2Vec算法的应用非常广泛,本文用其研究发言接序,依据“共现相似”取得了群友发言交互意义上的嵌入向量,进而采用降维、聚类算法进行可视化和进一步分析,得出了关于群友交互模式的一些观察结论。
在一个绝对理想的群聊模型中,每一个成员的发言相等,且无关于上一个或者上几个发言的个体身份。对于任何一个成员B在眼下出现的概率,P(B)都严格等于P(B|A),上一个或者上几个成员的发言都不会影响B发言的后验概率。
但正如自然语言不是特定集合内符号的平稳平均随机序列,发言接序也是一个具有极强的、非线性的自相关性的随机序列,在任何意义上都更接近一个n阶的马尔科夫过程。它和自然语言一样,存在着复杂的相关性结构。简单的来说,有些人只会参与围绕某些话题的讨论,或者会特别积极的参与某些话题的讨论(而话题本身也就模糊的确定了当前人员组成);有些人会伴随着另一些人的出现而出现,平时则保持沉默;同时成员自己也有一些参数,比如整体上对发言的倾向性、每天愿意花在聊天上的时间等等等。各种因素相互交叉掣肘,很难按照一种传统的方式或者结构主义的方式进行罗列和验证,或许只能通过统计描述的方式进行建模。
它和自然语言中词汇的出现当然也有很多不同点,比如容易形成两个成员交替发言、或者多个成员交替发言的“震荡”模式,也很容易出现一个人连续出现多条记录(本研究没有对这种情况进行特别处理)的“长叠词”模式。同时其随机性也毫无疑问更强,因为成员的出现可以毫无征兆,语料在整体上也不用遵守任何显性的“语法”,没有明确的结构和标识符。
当然,以上所作的仅是一些观察和猜测,还有待进一步的研究进行探讨和证实。除了这些发言接续本身特性之外,本研究也存在一些别的问题,可以作进一步的改良和思考:
并没有讨论语言内容本身。因而本研究并不是一个自然语言处理任务,只是借用了一个自然语言处理算法。事实上,对于“聊天记录”,本文采取了一种很买椟还珠的做法,完全丢弃了“聊天”,只在乎“记录”那一行。而真的对聊天语料加以分词和分析或许能让我们得到更多有趣的见解。对聊天语料进行自然语言处理本身并不是一件很新颖的事情,毕竟现在各种聊天机器人已经得到了广泛商用。不过,一般来说这种任务更在乎正确的生成和识别语言,而本研究的视角会导向更注重对不同个体的语言风格分析,是一种描述式的,更无监督的任务。一种最浅显的做法就是词云图:一些QQ聊天机器人其实已经具有此种功能。而更深入的做法或许也是用一种参数化的方法描述不同人的说话方式,将其投射到一个向量空间,并适用同样的方式来降维和聚类。
对不活跃的人物无法做出有效的嵌入和评估。通读全文之后,会发现“发言频数”,即“活跃度”的因素在各个研究模块中都构成了一定的问题。比如,在降维的过程中,这些非活跃“暗物质”就产生了干扰,在聚类的过程中也是。总体来说,这些嵌入是很欠训练的。多个人报告说“自己的向量近邻中有完全不认识的人”。这种现象是因为余弦相似度是一个对称的度量,A与B的距离和B与A的距离是一样的。而如果B恰巧是一个只说过一句话又是接着A说的,那么B的向量就会非常接近A,导致A观察到这个近义词。这种情况需要某种平滑操作,或者数据增广(Data Augmentation),加以解决,其本质是在数据集中加入很多“可能会存在”的聊天(Potentia),或者“替代世界线里的聊天”,以增加数据量,使模型摆脱对“现实数据”(Actus)的依赖,平衡其中的噪声,从而增强健壮性(Robust)。我能想到的操作有三种:第一种是基于某种平滑过的贝叶斯推断,从一个理想的先验分布中抽样,随机生成一些新接序。第二种是将实际记录本身抽象为一个转移矩阵(或者网图的邻接矩阵),并在上面随机游走来生成实际用于训练的接序。这就是一种图嵌入方法了,类似Node2Vec。具体做法是,将人视为一个个节点,统计某个人出现后下一个成员的概率分布,作为从那个节点出去到各节点的边权。第三种就是调用对抗性生成网络(GAN)这样的算法来生成高度拟真的接序。不过我觉得这三者效果都会差不多。
20年的数据丢失。目前在我询问的人中,没有人能提供2020年的记录数据。这非常可惜,因为其实相当一部分人最怀念的就是那时候的校群生态。我本人曾以“时间胶囊”的名义保存了2020年1月10日和2021年1月1日这两天的记录,但这些记录不是通过导出而是直接复制。这意味着不能进行QQ号对齐,而必须进行有风险的纯学号对齐……不仅如此,现有的数据有时候只是还原出了很多纷争。而如212-702的高相关性这样老群友耳熟能详的现象,现模型甚至都无法还原。
第一校群的最后一瞥:2020-1-10时间胶囊。一天后,延续8年的第一校群瓦解,直接有900多名历史成员丧失,活跃成员“衣冠南渡”重建校群,史称第二校群。
4. 数据的处理过于等时。其实虽然我们希望取得更早的记录,但是校群确实也处在动态演替的过程之中,这就要求我们在某些视角下不能将所有数据看做是处在同一个等时平面,而是要将时间远近的概念“硬编码”进我们的模型。一个理想的做法是让不同数据的权重随时间按照某种幂率衰减,越古老的信息对最后的嵌入产生越小的影响。比如我们可以设置一个“显著性半衰期”,每过这段时间之前信息的影响力的减半。
五.后记
4月15日B站原后记
校群现在感觉其实也挺没意思的,就那几个“核心区”“相关区”的人每天吹水一些无聊的事情,甚至都不太讨论学校本身的事情了。
但历史上,校群为不少疫情中苦闷的同学中提供了一个交流和玩耍的场所,也得以结识很多平时不太见的学长学姐、学弟学妹,因此我觉得还是有必要对其历史贡献进行肯定。该报告(显而易见的)就是献给我们的群主14668,精神领袖470,以及诸多群友们的。
我始终认为校群的未来是光明的,将始终能承担他联络校友的基本功能,也允许校友以其为平台创造更加辉煌的校群文化,正如更早的先辈们在华育中学吧创造了辉煌的华吧文化一样。事实上,我们的群主就是那个时代的过来人。
如果正在阅读这篇文章的您,非常幸运,是一位在第一校群崩溃时与组织失去联系的老同志,有意回校群看看,请私信我,我会很乐意领您前往。如果您是我们的校友,但此前未听说过校群,也想去看看,也同样。
也希望能通过这份报告,我们的校友小辈们,也能激发对机器学习技术的热情,走上AI技术的探索,并对其(尤其是NLP领域)涉及的的概念和思想有个初步的了解(欢迎和我交流,尽管我自己也就是个所谓的“调包小鬼”,我懂个P的机器学习,hhh)。24、25、26……届的新华育人们,你们虽然不少通过摇号录取,不要为此失了自信,坚信自己也会接续学校此前的辉煌,最终成长为社会的栋梁。现在上海四校似乎都要扩招,别的我不清楚,efz可是真的要设立11、12班两个“人工智能试验班”……
这个项目整体从4月10日开始策划,4月11日和12日在校群公开演示,后面三天断断续续的完成了本报告。
159
2022年4月15日于上海
6月23日E站转载后记
大部分在这里看到这篇文章的人都会想:你不是已经在B站发出了这篇文章了吗?我们都看过了,为什么又大费周折的移植到blog.nth.ink上呢?
答案很简单:E站是一个和华育有很强的联系的,以技术为主题的博客,而本研究又是一个和华育(华育校群)密不可分的技术项目,那岂不是非常契合吗?把这篇文章发上来给喜爱技术的校友们看看,何乐而不为呢?
同时,我们也想到20851忧国忧民的评论:中国互联网的产出或许已经愈发枯竭。随着若干大平台逐渐兼并所有的资源并且实现割据,进行互相排斥,大部分信息都不再存在于独立的网站或者论坛,而是依托于某些平台以特定的形式发布。随着活跃的网址的数目一再下降,过去那种各种论坛百家争鸣的盛况或不再现。当然这也可能就是互联网发展的必然规律和时代趋势。但不管怎样,我觉得我们应该给我觉得在严酷的现实下仍然怀有建站理想的nth同学一点支持,这是我在此处转载此文章的第二个原因。
在这篇文章发出后的两个月中,基于机器学习的校群学又得到了长足的发展,更多的数据被发掘,数据集被补全,更新的洞见从中产生,该项目也得到了【Huayu2Vec工程】的名号。这些新洞见,包括“校群生物学”所揭示的“二门五纲”分类结构更是对本文中初步的“校群三系”的补充和扩展,与其遥相呼应。这些内容都在H2V项目的第二篇论文《校群速通学、校群生物学、校群量化政治学》中介绍,这篇文章我也会稍后在E站发出。
六.参考文献
1. https://zhuanlan.zhihu.com/p/114538417 深入浅出Word2Vec原理解析 - 知乎
2.https://zhuanlan.zhihu.com/p/327699974 t-SNE:可视化效果最好的降维算法 - 知乎
3.https://zhuanlan.zhihu.com/p/31250283 【用Sklearn进行机器学习】第六篇 聚类:深入K-Means - 知乎
4.https://blog.csdn.net/HUSTHY/article/details/103164934 word2vec模型训练保存加载及简单使用_colourmind的博客-CSDN博客
5.http://bindog.github.io/blog/2018/07/31/t-sne-tips/ t-SNE使用过程中的一些坑
6.https://blog.csdn.net/li532331251/article/details/78203438 Python txt文件读取写入字典的方法(json、eval)_小天_2016的博客-CSDN博客
7.https://www.runoob.com/python/python-reg-expressions.html Python 正则表达式 | 菜鸟教程
8.https://blog.csdn.net/qq_34333481/article/details/88694185 python 分析qq聊天记录_蕾姆233的博客-CSDN博客
9.https://zhuanlan.zhihu.com/p/56542707 【Graph Embedding】node2vec:算法原理,实现和应用 - 知乎
(首发于B站)作者:佘山总督 https://www.bilibili.com/read/cv16155619 出处:bilibili
关于作者旅菇佘侨159
- 退学,成群结队,连连骂
- Email: jiazhibai@hsefz.cn
- 注册于: 2022-05-25 00:14:29
jzb太强了 膜拜大佬