
本文作者:Tianheng Ni
本文分类:计算机技术 浏览:1500
阅读时间:1593字, 约2-2.5分钟
看了之前的一篇文章(复活庆典:MockingBird拟声鸟AI拟声项目(1) - Ericnth的小站),文中作者提到的MockingBird软件就是深度学习的一个典型例子(模仿语音语调)。可惜的是,这位作者的电脑是一台核显笔记本,没有独立显卡进行加速,因此他不得不使用CPU进行运算。在运算过程中,他发朋友圈吐槽了该过程的缓慢以及CPU的高温。可见在深度学习的领域,GPU是必不可少的;那它有哪些CPU所不具备的优势呢?

我们来看一下Nvidia官网提供的数据。可以看到,在目前新的30系列GPU中,即使最低端的3050都有数千个CUDA核心,数十个流处理器。而看一下你的CPU,哪怕是几乎现在最大碗的AMD TR 3990X(线程撕裂者),也只有64核心128线程,你家电脑上的CPU则很可能只有4个或者8个核心。
神经网络是深度学习的核心, 而神经网络是高度并行的。因此,便宜大碗的GPU就非常适合进行深度学习。并行运算我个人粗浅地认为很像多线程,实际上也就是把一个很大的任务拆分成很多很多的子任务同时计算,而没有必要等一个子任务完成再进行下一个。什么情况下可以同时进行计算呢?当任务间相互独立时。如果任务B需要依赖任务A的结果,那我们不得不等待任务A运行完毕才能开始任务B。到这里你也应该可以类似地理解为什么GPU可以加速视频画面渲染等一系列道理了。

简单说一下什么是神经网络(准确来说是人工神经网络,ANN):就是一堆输入数据加上权重,处理后会形成一个类似于人脑中神经元连接的东西。能使机器有简单的决定能力和判断能力,可以解决计算机视觉、语音识别等传统编程方法很难解决的问题。
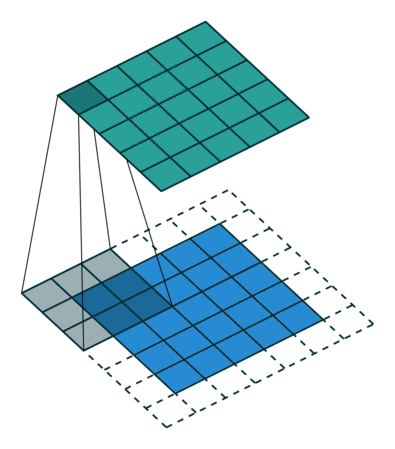
这个动画展示了没有数字的卷积过程。我们在底部有一个蓝色的输入通道。在输入通道上滑动的底部有一个阴影的卷积滤波器,还有一个绿色的输出通道。 - 蓝色(底部)- 输入通道 - 阴影(覆盖在蓝色上)- 3*3的卷积过滤器 - 绿色(顶部)- 输出通道
对于蓝色输入通道上的每个位置,3x3过滤器进行计算,将蓝色输入通道的阴影部分映射到绿色输出通道的相应阴影部分。
在动画中,这些计算一个接一个地依次进行。但是,每个计算都是独立于其他计算的,这意味着任何计算都不依赖于任何其他计算的结果。
因此,所有这些独立的计算都可以在GPU上并行进行,从而产生整个输出通道。
这让我们看到,卷积运算可以通过使用并行编程方法和GPU来加速。
来源:https://zhuanlan.zhihu.com/p/106669828相比于CPU,GPU可以说是超超超大杯了,那为什么还需要CPU呢?
虽然GPU核心非常多,但这只是“跑量”的,单独拎出CPU和GPU的一个核心进行对比,那GPU必定是相形见绌。而在很多的情况下,计算机进行的运算并不能同时进行,依然需要完成一个工作再进行下一个(比如有不少游戏就很吃CPU单核性能)。也有很多情况,需要的任务非常简单,然而此时如果还将数据通过PCIe接口送至GPU进行运算,完成后再将结果送回CPU,那反而浪费了大量路上的时间。总之可以看到,GPU的特长是解决并行的、大型的问题,并不可以取代CPU的地位。
总的来说,现在进入人工智能的时代,GPU必将大放异彩。现在几乎所有的深度学习框架,包括TensorFlow和那篇文章中用到的PyTorch,都可以使用GPU加速。Nvidia很早之前就预见到了这一点,然后开始布局,也就诞生了CUDA架构。NV也在人工智能中起到了引领作用,有Tesla加速卡还有Jetson嵌入设备等产品线,赚了不少,可惜AMD(ATI)在这方面就显得有些落后了。
最后不知道说啥了,反正希望老黄能让大家都买到原价的非矿显卡吧!40系列也快了,不知道会啥样,反正肯定得抢疯~
关于作者Tianheng Ni
- 卑微站长23564~ 苣蒻OIer,电脑爱好者,喜欢C++编程/折腾网站
- Email: eric_ni2008@163.com
- 注册于: 2020-04-05 07:11:36
其实mockingbird也用到了TensorFlow(TensorFlow和pytorch都是支持Linux上的amd显卡加速ROCm的)
21172以前评论道:“CPU就像一位数学教授,他能一个一个解决各种各样的艰深的问题,而GPU像几百个小学生,每一个做不了很难的题目,但是加起来计算能力也是相当客观的。”
@AntonyJia 比喻的,精辟的,正确的